by Clavance Lim, MSc Student in the Department of Computing
Translating words to numbers
As humans, one way in which we are unique is our ability to communicate with complex language (arguably, science students possess this skill too). In contrast, computers ‘think’ not in language, but in binary numbers. Instead of the decimal system we count with, which uses the ten unique digits ‘0’ to ‘9’, computers ‘think’ only in ‘0’s and ‘1’s. This is because their hardware is controlled by tiny switches, which turn electrical current on or off. As it is difficult to control electrical current at such a microscopic level (switches can be as small as only 10x the size of an atom!), the hardware only works with two states, ‘on’ and ‘off’, which correspond to ‘0’ and ‘1’. So everything we do on a computer – from pressing a single key on the keyboard, to watching a movie – has to be converted to a series of instructions in the form of ‘0’s and ‘1’s.
In recent years, there has been some hype surrounding the pursuit of ‘artificial intelligence’, or the creation of computers or machines to perform tasks requiring human intelligence. To achieve this, any task must be represented in the form of numbers, for the computer to process it. Thus, one question the field of natural language processing faces is: how do we translate words to numbers, while allowing words to retain their linguistic meaning?
A key breakthrough has been to design algorithms which convert each word to a vector (which is simply a row of many numbers). A famous example of the success of this approach is when researchers managed to show that the vectors for ‘Man’ deducted from ‘King’ plus ‘Woman’ resulted in the vector for ‘Queen’.1
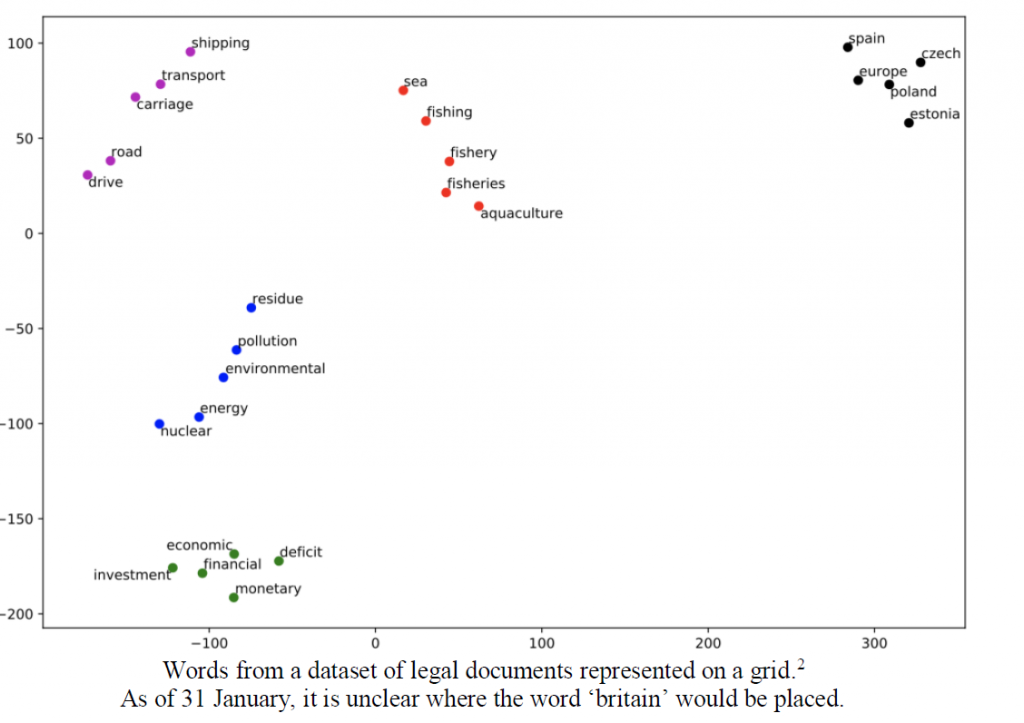
Part of my education at Imperial has been to examine the application of this to legal documents, a field in which language is particularly important. For example, we can see that even when mapped to a small grid, words which have similar meanings are placed closer to each other.
Meaningfully representing words as numbers unlocks the potential for computers to do much more. For example, using a much older method,3 the first paragraph of this essay was summarised as:
“Instead of the decimal system we count with, which uses the ten unique digits ‘0’ to ‘9’, computers ‘think’ only in ‘0’s and ‘1’s. So everything we do on a computer – from pressing a single key on the keyboard, to watching a movie – has to be converted to a series of instructions in the form of ‘0’s and ‘1’s.”
This already seems to capture the gist of the paragraph. With current research, the aim is to accurately summarise documents not only by picking out the most important sentences, but by rewriting the entire passage using words unseen in the text itself. From distilling complex articles to designing intelligent chatbots, the potential of this research is tremendously exciting.
References:
- Mikolov et al. (2013), Efficient Estimation of Word Representations in Vector Space, available at: https://arxiv.org/abs/1301.3781
- This diagram is from my dissertation, available at:
https://www.imperial.ac.uk/media/imperial-college/faculty-of-engineering/computing/public/1819-pg-projects/An-Evaluation-of-Machine-Learning-Approaches-to-Natural-Language-Processing-for-Legal-Text-Classi%EF%AC%81cation.pdf - Mihalcea and Tarau (2004), Bringing Order into Texts, available at: https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf