Have you ever filled a form where you got an “invalid email address” error? These alerts are commonly built using regular expressions. They evaluate the field value against a set of rules and report if the value complies with them. Regular expressions allow much more than this simple example.
I was introduced to regular expressions (RegEx for short) in 2009 when studying Finite Automaton. A Finite Automaton (aka Finite State Machine (FSM)) is a state machine that accepts or rejects input based on a set of rules. The example I found most interesting is the concept of an arcade Galaga machine that would, in the 80s, accept a coin as the input. It would return you a credit to spend on the game if the coin was 10p. If the coin was another coin, it would reject the input and return the coin back to you.
One of the most know automaton machines was Alan Turing‘s Turing machine which was used to break the Enigma machine in the 1940s. Regular expressions came shortly after in 1951 by mathematician Stephen Kleene, and its first know application was made in 1961 by Ken Thomson on his Unix text editor “ed”.
How does RegEx work?
RegEx uses a search pattern that can match, replace and manage text. It can significantly simplify going through many text files, logs, spreadsheets, etc. I love using it in my code when I need to match, select and manipulate objects. Very useful in XPath, python and PowerShell scripts.
RegEx syntax summary
Literal characters: Except for special characters all characters match their literal characters. E.g. the regex for "A" matches the string "A", "9" matches the number 9, "=" matches "=", etc.
Special Characters: ., +, *, ?, ^, $, (, ), [, ], {, }, |, \.
Escape sequence: If you need to match any of the special characters, you need to add an escape character "\". E.g. "\\" will match "\" and "\[" will match "["
OR operator "|": you can try to match multiple strings like "Robert|Rob" this will match any of the words "Robert" or "Rob"
Metacharacters:
. will match any single character
\d will match any single digit
\D will match any NON single digit
\w will match any single lower/upper case A to Z and 0 to 9
\W will match any single NON lower/upper case A to Z and 0 to 9
\s will match any single space
\S will match any single NON space
Position Anchors:
^ start of line
$ end of line
\r carriage return
\n line feed
Laziness matching:
. any single character
* multiple times
+ one or more times
? zero or more times
{,m} between 0 and m times
{n,} more than n times
{n,m} between n and m times
Capturing groups:
() will capture a back reference to the regex within the parentheses. You can access these by referencing them as E.G. \1, $1, {1}, etc, depending on the language/tool used.
Powershell:
# How to show any occurrence of the word error in one folder
Get-ChildItem -Path $logFolder | Select-String -Pattern 'Error'
Python:
# How to click on an a HTML object using Python and Selenium
driver.find_element(By.XPATH,"//a[i[contains(@value,'objName')]]" ).click()
You can try regular expressions straight from your browser. I found it useful when automating web checks or completing web scraping activities. If you use Chrome, press ctrl_shift+i (F12 in most browsers) to open the developer tools. In the “console” tab, you should be able to identify if an element exists by typing "$x('expression')" and Chrome will let you know if the element exists.
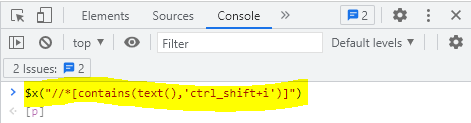
This can also be tested within the “elements tab”:
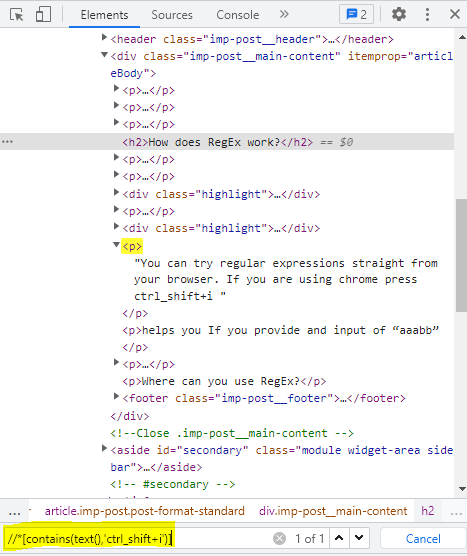
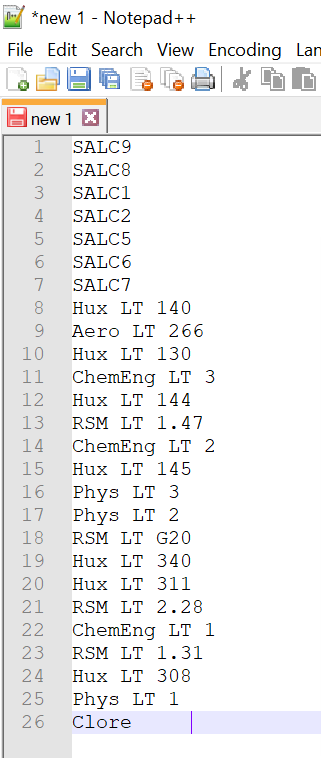
I also tend to use it with text editors (Notepad++, Geany, etc.) for quick text cleanups. As I was writing this, I wanted to add the entire list of rooms available on a form list box existing in one of the ICT events systems. I could have typed them one by one, but that is not a good way to do it if you have more than a handful of entries. I’ve copied the HTML element I wanted and used Notepad++.
I wanted the room names just like the ones highlighted below:
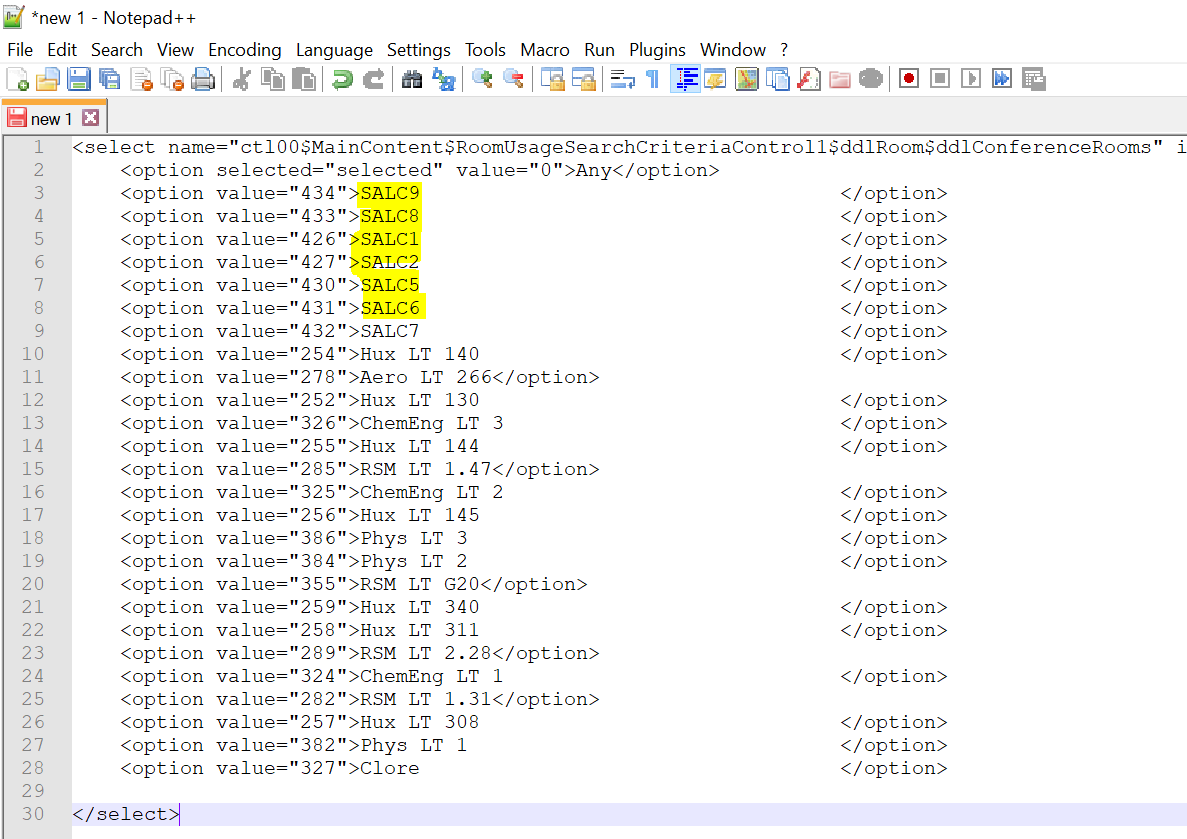
Using the “Replace” option under the “Search” menu on NotePad++ and having the “Regular Expression” option ticked, I typed ^.*([0-9a-zA-Z. ]*)[\t ]*+ and replaced it with \1:
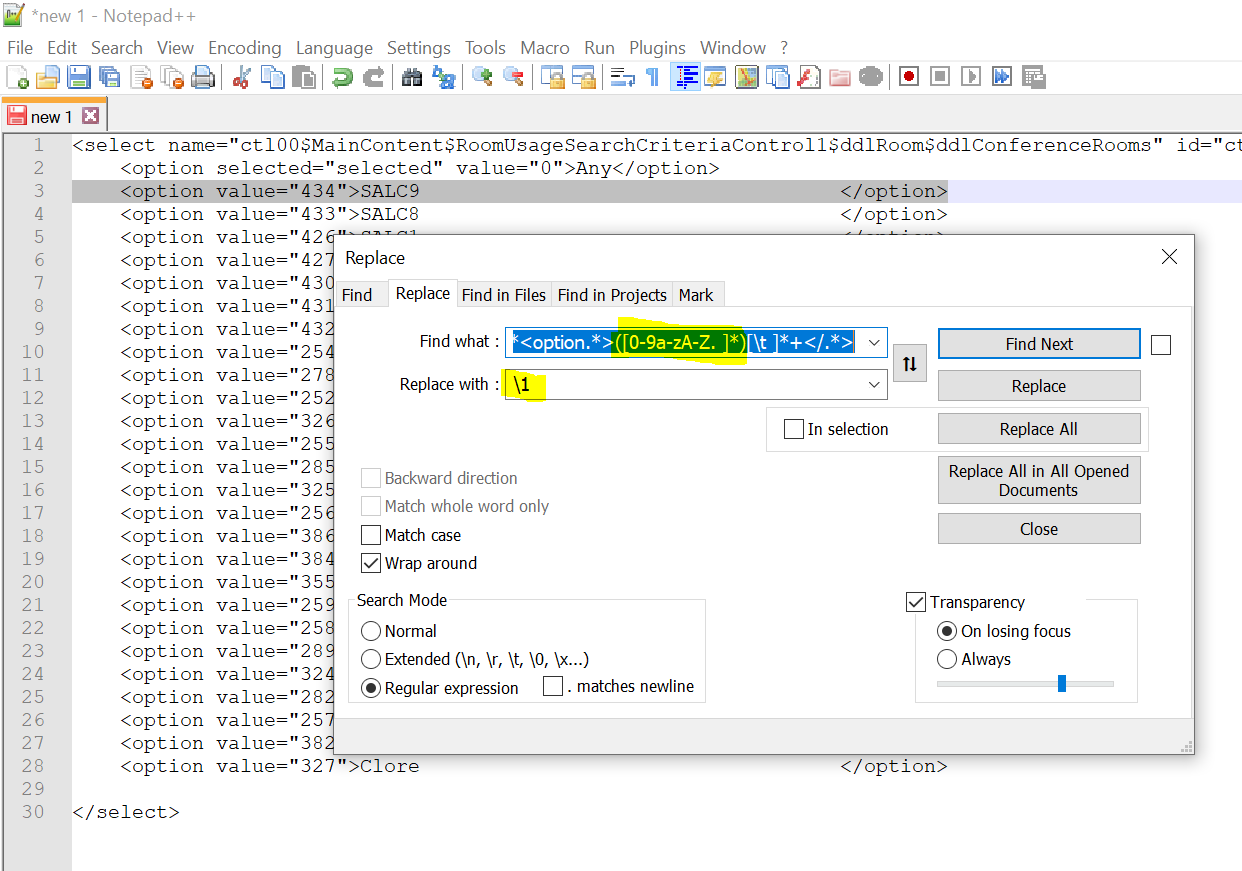
^.*<option.*>([0-9a-zA-Z. ]*)[\t ]*</.*> is signalling to the search and replace function that I wanted to find:
- start my search from the beginning of the line
- has any number of caracters before it encounters <option
- has any number of caracters before it encounters >
- This part is a group because it is wrapped with (). Looks for any word of any length composed of numbers, lower/upper case characters from A to Z, dots and spaces.
- has any number of spaces
- has any number of characters between <>
The replace box signals that the entire word match should be replaced with the first group encountered in the match. The result can be seen as:
Conclusion
There are hundreds of sites explaining RegEx but I’ll point you to the reputable Microsoft page: https://docs.microsoft.com/en-us/dotnet/standard/base-types/regular-expression-language-quick-reference for reference.
The potential for using RegEx is immense. Have you used it before? Any good examples you can share?