At the very, very beginning, let us see what thermodynamics up to: This is a science investigate the 1. To which forms energy goes to, and 2. how to make energy useful. Let us start from the first issue. It is a common-sense that energy consists of mainly to forms: (ability to do) Work and (ability to release) Heat. The former one corresponds to a directed, ordered moving, in contrast the latter shows a chaotic movements (in statistical physical sense).
Thus we have the first law. It said that the change in total energy should be decomposed to heat and work.
Since industrial revolution, the requirement of human on work rapidly increases, even (say) exceed the need on heat. This relates to the second objective of thermodynamics: How to make energy useful. More specifically, we wanted to discover the convection laws better work and heat.
To achieve that, we first need to identify what energies are useful. One may dream of convert thermal energy to work with infinitesimal cost, or in other word, convert an object’s thermal energy completely to work. However, this is not that useful (and, in fact, impossible) : one need to “recycle” the row material , that is why we are interest in thermodynamical “cycles”. We wish for each cycle, the working substance can come back to its original “state” (For a state, we tried to find all what we called states variables that thermodynamically we cannot tell the difference between two substances with identical values of state variables). Our task is thus, identify the condition which a completely restored to the original state, while making useful effect, is possible.
It is a common-sense that under some conditions our processes are dissipative, i.e. energy flow out regardless either direction we undergo in the process. Dissipative work includes friction, and dissipative heat includes heat lost. For instance, say we have a random process that involve (mechanical)work done. Let us further assume that the process involve at least one (either pressure of the object or the pressure of the surrounding) well-defined pressure. Whatever the process is, if originally (without friction) we expect the process can go back to the original state (both system and surrounding) following the same path (We call this reversible), this time with friction we have the pressure deviated higher from the path in the forward process and deviated lower from the path in the reverse process. This means it is no more reversible. Similarly, processes involving heat dissipation are again, irreversible. (We can show it quite generally)
There are other processes without dissipation that are irreversible. But as we have found out, reversible processes guaranteed non-dissipative nature, it means that we should be interested in these processes. Thanks to the study in heat engine by Carnot, we have a well-establish example of reversible processes: Carnot cycles. From the definition of Carnot cycle and another important statement: The second law of thermodynamics, one can derive the complete picture of basic thermodynamics, as we will discuss later.
One easiest approach to the second law is using microscopic point of view (Although is had not been understood by the physicists in the 19th century yet): Through a diffusion process, heat can indeed only spontaneously flow from hotter to colder objects, not reverse. This is Clausius’s statement of the second law. One can show that it is equivalent to the Kelvin-Plank’s statement. Using Clausius’s statement, one concludes that a reversible heat cycle operating between two reservoirs (apart from the trivial one: The one goes back to the starting point with identical path) should have the same efficiency as the Carnot’s cycle, which is naturally a maximum efficiency one can achieve as a heat engine. Reversible heat cycles as we defined, are thus indeed the most particular type of cycles (and in fact are fictitious) and are indeed the type we are seeking.
Either using the efficiency relation (require the process is quasi static so that we can draw a path) or using the Kelvin’s statement, we can derive Clausius’s theorem for any closed cycle. On the other hand, it is easy to observe that any two points on the P-T-V diagram can be connected by reversible processes (If a states equation exist). Thus we can use Clausius Theorem to induce that for any two points on P-T-V diagram there exist a fixed quantity, if we set the quantity at one point is zero, then this quantity is well-defined in the entire space and independent on the path — from now on we call it entropy.
Since entropy and internal energy are both state variables, from the first law we conclude that for irreversible process, heat is always less than the corresponding reversible heat and thus work, must be greater than the corresponding reversible work.
Read Basic Thermodynamics in full


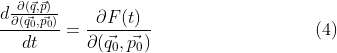
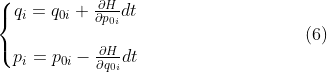
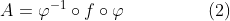
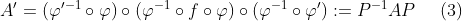

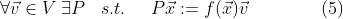
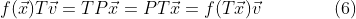
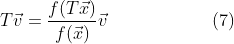




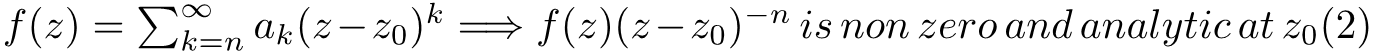
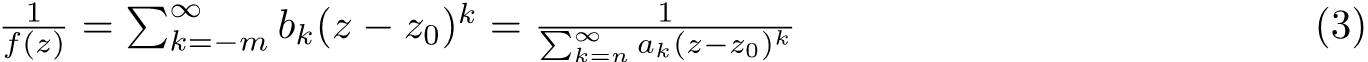
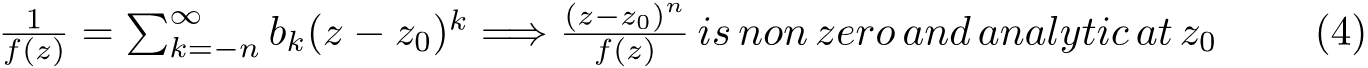
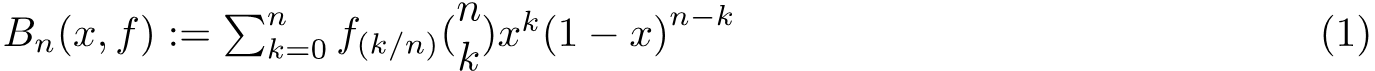



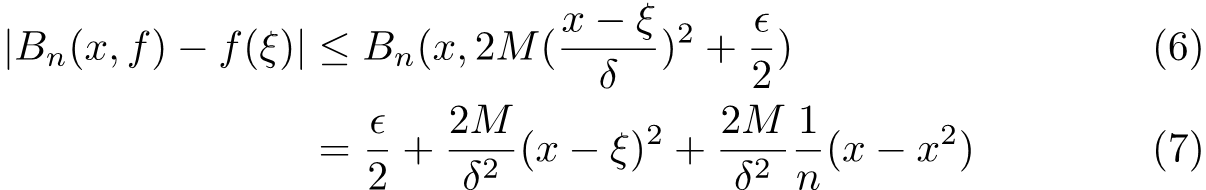 In the second line above we putted the first term of the function into the expression of the polynomial and it came out will some calculation. Obviously, we need to set x=ξ to proceed and this yields
In the second line above we putted the first term of the function into the expression of the polynomial and it came out will some calculation. Obviously, we need to set x=ξ to proceed and this yields




