Hi, I’m Hamish; I’m from Watford, UK, and I’m in the second year of Computing. In my free time I enjoy studying foreign languages, playing water polo and doing Competitive Programming. This year I’m behind Imperial CyberSoc and CTF Team. Let’s connect on LinkedIn!
A few months ago, I took the train to Oxford with a school-friend. Rolling through the picturesque Chilterns, the sun streaming through the window, and as the fans of GBRJ that we are, we proposed visiting more UK cities by train. Yet, existing booking sites wouldn’t let us sort destinations by price. Fine, we thought: a bit of programming will solve this. It also happened to explain a long-running enigma – why UK train prices seem so random:

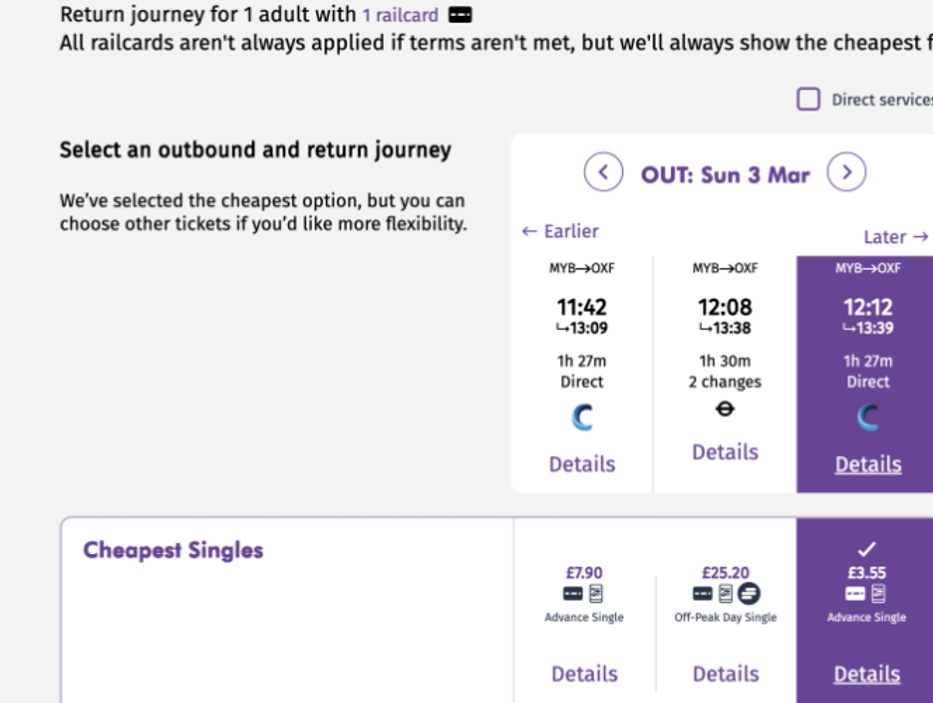
Thanks to Chiltern Railways for (not!) sponsoring this video…
National Rail publishes open fare data, and various programs have been distributed to process it, from librailfare and Avantix Travelller (old data format) to BR Fares (web API unsuitable for our query volume).
The most promising implementation I found was @FedericoBotta’s railfares which, although using the new data, computes ‘isocosts’ rather than journey costs. It therefore didn’t seem to consider ‘split-ticketing’, changing train, or non-reversible fares. I also struggled to make it run quickly on my computer: problematic when examining fares from all tube-accessible stations. Time, then, to write some C++.
Things started off swimmingly with some rudimentary code to import the data, and I ran Dijkstra’s algorithm to compute the cost to every station with unlimited changes. This gave interesting results. I could reach most UK stations for less than £20, even Glasgow for only £14 one-way:

But closer review revealed a snag: my access to virtually all Northern stations hinged on this mysterious ‘NXP’ ticket to Retford for only £8. The wonderful BRFares identified it as LNER’s “flat fare” advance, but alas on their website it was nowhere to be booked. A twitter response from customer support confirmed that these are special tickets in limited numbers (often 0!).
This proved a recurring theme as I tried the tickets my program proposed. Almost all cheap rail tickets are quota-controlled “Advance” fares. While commonly available, they typically have >20 different price points and without the quota (RARS) data, choosing the correct one is impossible.
After much frustration, I resigned to only Anytime and Off-Peak tickets. These are so expensive they are useless, but at least I could check the results:
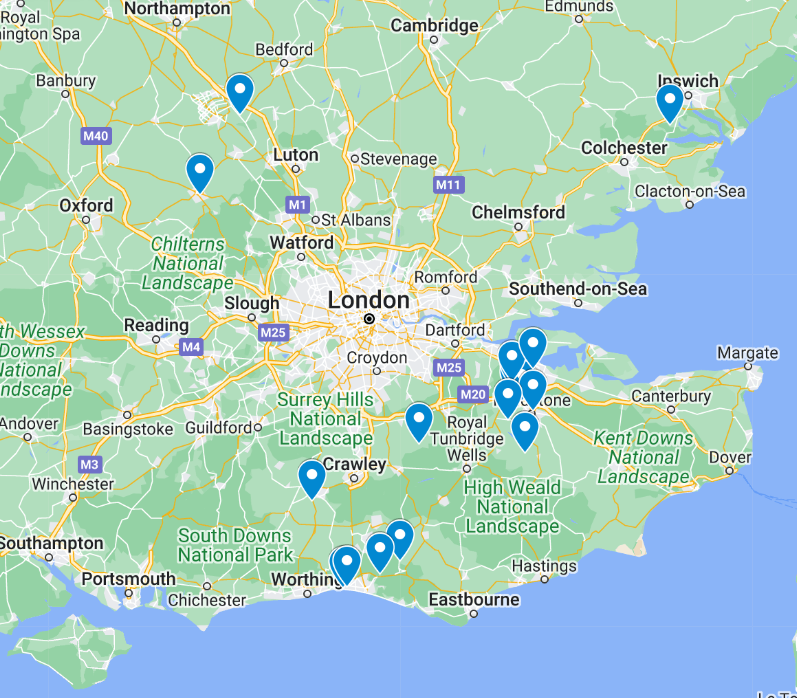
Furthest stations from London for £<20, only “walk up” fares, unlimited changes.
Another issue with my first attempt was the runtime (>25s). Even if my program didn’t compute quite what I wanted, I could still optimise it to learn from it.
In the end I reduced it to <1s by:
- Pruning NLCs1
- Turning on -Ofast (controversial… but pretty safe) (10s)
- Manual (not mktime) date parsing (surprising) (2s)
- Storing ticket codes as char[][][] instead of vector<vector<string>> (also surprising: usually vector and string are fast, though 10M iterations, -0.1 μs / iteration saves 1s) (< 1s)
I also tried memory mapping (slower) and profiling (didn’t help: most code was I/O or DLLs).

In conclusion, we failed – without accurate Advance quotas we still don’t know where to take our next rail journey! But this was still worthwhile because it has inspired me to take Performance Engineering next year.
I also hope it makes the case for Open Data to give consumers the flexibility of their own use cases. It’s been 19 years since this report suggested a more transparent quota system, so I’m doubtful it will happen, but hopefully projects like this show its potential.
This was my last post for AY 23/24 – I really hope you enjoyed them and have a great summer!
Full code: https://github.com/starswap/trainpricing/.
1 National Location Codes identify stations and other features on the rail network. I removed all irrelevant non-station ones.