The Research Data Management service, based in Central Library, has ‘hit the ground running’ at the beginning of 2017. The RDM team will present a series of brief lunch-time talks, the ‘Byte-Size Sessions’, with the first taking place on February 14th. Then, on 17th March, we will host the second ‘Data Circus’, a College-wide showcase of open data and software.
Data and software are crucial materials for, and products of, research, underpinning scholarly communications. In recent years, funders such as the RCUK and the Wellcome Trust have mandated data publication and data sharing with as few restrictions as possible. For instance, the Wellcome Trust Policy on Research Data (2014) states:
‘Making research data widely available to the research community in a timely and responsible manner ensures that these data can be verified, built upon and used to advance knowledge and its application to generate improvements in health.’ (reference)
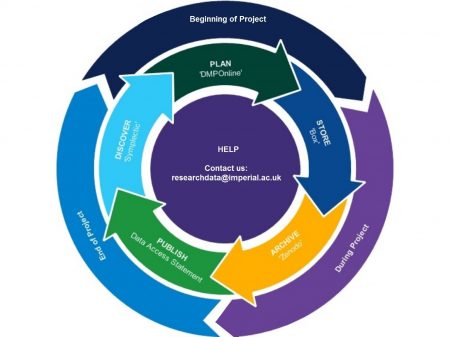
As research data generates increasing interest, sharing and re-use, instilling good practices for research data management has become important at all stages of the research process. At Imperial, the Research Data Management Team have developed a workflow which follows the lifecycle of research data through all of its stages; from data planning and creation, through to long-term data archiving, data publication, and data sharing, as per the workflow (Fig. 1).
Fig.1: The Research Data Management workflow at Imperial College follows the ‘life cycle’ of research data from the initial planning stages of a research project, through to publication, data sharing and long-term archival storage of research results.
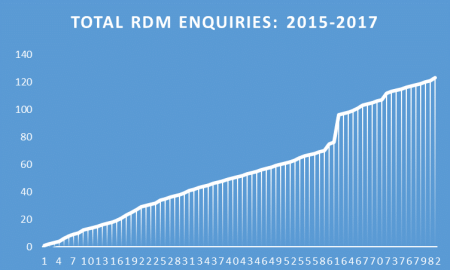
The Research Data Management service has seen a steady increase in the number of queries since its inception (Fig. 2). These queries cover numerous aspects of research data management and the workflow at Imperial, but the most frequently-asked questions are about writing Data Management plans and creating data access statements.
Fig. 2: The RDM Team has seen a steady increase in the number of enquiries. These enquiries have been mediated through e-mail, telephone and face-to-face meetings.
The Research Data Management Team have been actively involved in outreach, promoting best practice in research data management. We have achieved this through tutorials, webinars, lab group and departmental visits, face-to-face meetings with researchers and faculty, and events such as Research Data ‘Clinics’. It has been a successful first year for the Research Data Management Team at Imperial, and we are looking forward to the year ahead.
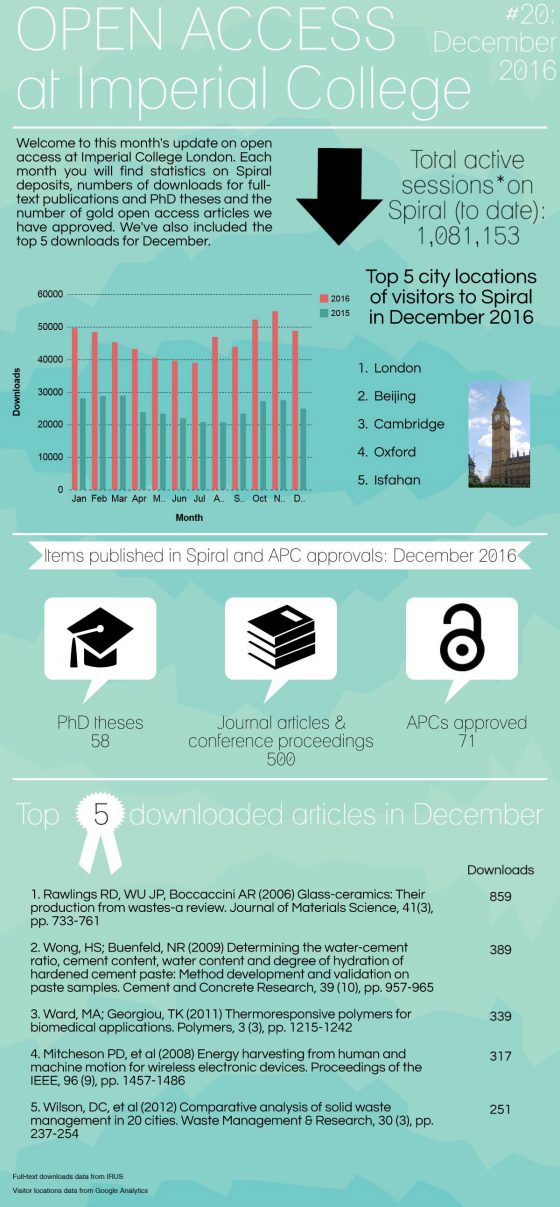
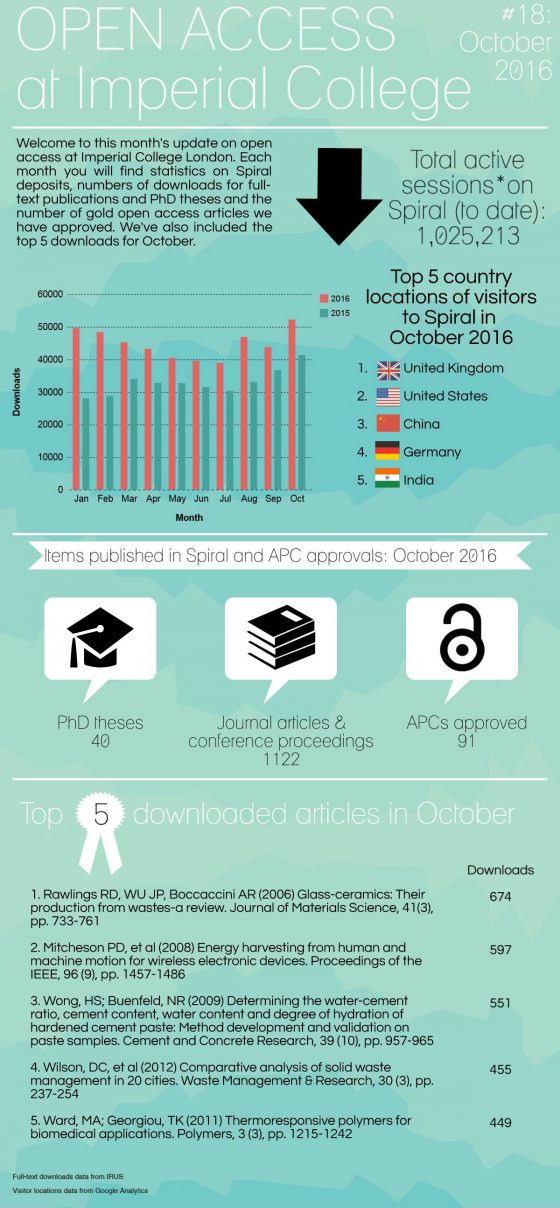
The open access team was formed in May 2015 and began collating statistics on its open access activities in June 2015, primarily to monitor deposits to our repository, Spiral, as well as gold open access applications. Our statistical analysis over the 14 months period shows an increase in all open access activities including deposits to Spiral, Open Access applications and downloads from Spiral. We are really pleased with the results, as it highlights the progress the team has made through our advocacy work and it is something to celebrate during International Open Access Week 24th – 30th October 2016.
Earlier today Imperial College submitted its annual report on compliance with the Research Council’s open access policy to RCUK. The RCUK OA policy envisages a five year journey after which 100% of RCUK funded scholarly papers should be available as open access in 2018. To support the transition to open access, RCUK have set up a block grant that makes funds available to institutions to cover the cost for article processing charges (APCs) and other OA-related expenses. Funds are awarded in relation to RCUK research funding for institutions, and Imperial College has the second largest allocation, just behind Cambridge and followed by UCL. The annual reports to RCUK give an overview over institutional spend and on compliance.
The headline figures for the 2015/2016 College report are:
£1,051,130 block grant spend from April 2015 to March 2016
89% overall compliance, split in 31% via the gold and 58% via the green route
570 article processing charges paid at an average cost of ~£1,800
The top five publishers are: Elsevier, Wiley, Nature, ACS and OUP
Like every year when discussing the RCUK report figures I think it is important to highlight that compliance rates between universities cannot meaningfully be compared without understanding the data sources and methods used. Just to give one example: the College could also have reported 81% green and 8% gold from the same data.
Why do I caution against directly comparing the numbers? For starters, research-intensive universities find it difficult to establish what 100% is. With hundreds, or in the case of Imperial College many thousand papers published every year we rely on academics to manually notify us for each paper who the funder is. Even though the College has made much progress improving its processes and data over the past few years we have to acknowledge that data collected through such a process will never be complete or fully accurate. For the College report we decided, like in the previous years, to base our analysis on outputs we know to have been RCUK-funded. For this year the size of the sample was 1,923 papers (compared to 1,326 in 2014). With a different sample the numbers would have been different, and other universities may have taken a different approach to analysing the data.
Sadly, it is currently not easy to establish whether an output was made available open access. Publishers do not usually add licensing information to metadata, and searching for manuscripts deposited in external repositories is possible but not necessarily accurate. The process we used for analysis was:
Cross-reference the sample with the journal list from the Directory of Open Access Journals; class every article published in a full OA journal as compliant ‘gold’.
Take the remaining articles and cross-reference with the list of articles for which the College Library has paid an APC; class all those articles as compliant ‘gold’.
Take the remaining articles and cross-reference with the outputs from ResearchFish that show a CC BY license; class all those articles as compliant ‘gold’.
Take the remaining articles and cross-reference with list of outputs deposited in the College repository Spiral; class all those articles as compliant ‘green’.
Take the remaining articles and cross-reference with list of outputs that have a Europe PubMed Central ID; class all those articles as compliant ‘green’.
As in previous years we also put remaining outputs through Cottage Labs Lantern tool but this showed no additional open access outputs. The main reason for that, I suspect, is the high compliance via the green route: some 81% of outputs in the sample had been deposited to the College repository Spiral or to Europe PMC. As the College prefers green over hybrid gold it would have been in line with our policy to report them as green, but as the RCUK prefers gold OA we decided to report all outputs know as gold as such, like in previous years.
I could write more about reporting issues around open access, but as I have done that on a few other occasions I refer those who haven’t suffered enough to my previous posts.
One other caveat should be raised for those planning to analyse the APC spend in comparison with previous years: The APC article level data is based on APCs paid during the reporting period. This differs from the APC data reported in the previous period which was based on APC applications published. There are, therefore, a small number of records duplicated from the previous year. These have been identified in the notes column.
“At a research-intensive university like Imperial it is hard to do anything that doesn’t involve data,” noted Imperial’s Provost when he launched the KPMG Data Observatory last year. The importance of data in research is now commonplace, from proclaiming the rise of a scientific Fourth Paradigm to celebrating “data scientist” as “the sexiest job of the 21st century” and research funders mandating research data management (RDM). Comparatively, software has received less attention – and yet without software there is no data, certainly no “big” data, and no data science either. In fact, there may well be no ‘modern’ research without it – in a 2014 survey 7 out of 10 researchers said it is now impossible to do research without software.
“Better Software Better Research” – SSI, licensed CC BY NC
Despite the importance of research software, academia could improve its support for academic coders. A university career is usually measured on publications, citations, grants and, perhaps, teaching. Focusing on keeping the tools of a research group up-to-date is not likely to give you either, and highly paid industry posts may be more appealing than short term academic contracts.
When I was a student and part-time university staff I was one of the people who developed and maintained digital research infrastructure. At the time, senior colleagues advised us not to risk our careers by becoming ‘mere technicians’ instead of doing ‘real’ research. This attitude has since changed somewhat, but beyond research support roles the career paths for academic software developers are still murky and insecure.
Thankfully, there are now initiatives dedicated to change this. One of them is the UK’s Software Sustainability Institute (SSI), a fantastic organisation with the simple yet powerful slogan: “Better Software, Better Research”. In 2015 I became a fellow of the SSI, and through this blog post I report on some of my related activities.
Supporting Research Software Engineers
Organisations like the SSI help to create a professional identity for coding academics, or research software engineers, as they are now called. One of the recent achievements was the formation of a UK RSE community as a first step to professionalization. Imperial College now has its own RSE group, and I am pleased that I had a chance to contribute a little to its formation. The focus of my fellowship activity was on improving College support for academic software development, and I approached this through policy.
In recent years, UK research funders released a set of policies governing academic research data management. This led to universities defining their own policies and making plans for the corresponding support infrastructure. At the heart of Imperial’s RDM policy is the requirement to preserve the data needed to validate academic publications – reproducibility is a core principle of research, after all. During the policy development I suggested that we should go a step beyond funder requirements to include software. Without code, after all, there is a risk that data cannot be understood. In some cases, the code is arguably more valuable than the data generated by it. This led to our policy requiring that where software is developed as part of a project “the particular version of the software used to generate or analyse the data” has to be archived alongside the data.
One of our principles for policy development was that there would be no College requirement without us providing – directly or indirectly – solutions that enable academics to comply, and that we would seek to add value where possible. This brought up the question: how do you facilitate the archiving, and ideally wider sustainability, of research code?
One answer, in general terms, is: by supporting best practice in software development, in particular the use of version control. Being able to track contributions to code makes it possible to give credit. Being able to distinguish different versions allows researchers to archive the right code. Running a distributed version control system (DVCS) makes it easy to open up the development and share code.
In informal consultation academics pointed to the open source DVCS Git – not surprisingly perhaps, considering its global popularity. We knew from anecdotal evidence that a broad range of DVCS are used at the College. Some academics pay for commercial solutions, others use free web-based options and some groups are hosting their own. There is no central support and coordination, leading to inefficiencies and, to an extent, a lack of central College engagement with academic coders.
Imperial College survey on distributed version control
To better understand current practice, I worked with colleagues in ICT to develop a survey aimed at DVCS users across the College. We launched the survey in November 2015 and circulated it via the RSE community, academic champions and email newsletters. 263 completed responses were received – for what some would call an “esoteric” topic this was a very good response, especially considering that we only approached a fraction of our 4,000 academics directly. The responses also showed that it was not just the usual suspects, such as computer scientists, who have an interest in DVCS (fewer than half of the responses came from the Faculty of Engineering).
Results summary
96% of respondents were aware of Git, and 82% actively use it
The main alternatives to Git are Subversion (65 users), Mercurial (18) and CVS (17)
Of the active Git users:
75% were rating themselves as expert or intermediate
91% use Git for academic research, 22% in teaching and 18% for commercial work
50% use Git for both closed and open development, and about a quarter each use it only or mostly for closed or open development
The main uses of Git are: code/documentation (99%), data/documents (53%), managing configuration files (35%), data sharing/sync (34%), backend for wiki/blog etc. (19%)
GitHub is by far the most popular Git web-repository (79%), followed by Bitbucket (45%) and Gitlab (22%)
Sample survey question: How do you use Git? (check all that apply)
We were particularly interested in finding out whether it would be worthwhile for the College to invest in GitHub, the hosted Git environment. GitHub is free to use, as long as you don’t mind your code being publicly accessible; there is a charge for private code repositories. Some respondents expressed a preference for a College-hosted open source solution or other platforms such as Bitbucket, but many comments pointed to GitHub. Overall there was a consensus that DVCS should be, to quote a participant, “a vital part of e-infrastructure” for an institution like Imperial.
A key requirement that emerged from the consultation was being able to run private code repositories, for example for “codes with commercial or security (e.g. nuclear) related sensitivities”. I am aware that open versus closed can be a controversial topic, but as an organisation with significant industry funding we have to acknowledge that some code cannot be made available publicly. Or, as one respondent put it: “Having a local GitHub Enterprise would definitely add value for us, as we’re working with commercially sensitive data through industrial collaborations, which we can’t put in a publically accessible repository or project management site.”
DVCS like GitHub make it easy for academics to collaborate and share. However, academics value platforms that preserve the integrity of the code while giving them control over what to make publicly accessible and when. The survey pointed to GitHub Enterprise as the preferred platform, a view that was fully endorsed by academics on the College’s RDM steering group.
Following the consultation, the College has made the decision to procure a site licence to GitHub Enterprise. GitHub Enterprise will become a core College service, managed by ICT. There would be no requirement to use GitHub for development, although its use will be encouraged. It was also agreed that we would not simply launch a new out-of-the-box service and hope that that would magically fix all issues. Instead some level of centrally coordinated support and training would be provided – ideally working with groups like the SSI and Software Carpentry. As a first step of the project to launch GitHub Enterprise, focus groups are being set up to gather academic requirements and guide the configuration and introduction of the new service.
Ongoing engagement
Arguably, this does not address concerns about career paths and reward systems for research software engineers. However, it demonstrates that a university like Imperial College values the code written by its staff, and is dedicated to support academic developing of research code. Partly as a result of the consultation, ICT, Library and the Research Office have now increased their engagement with the RSE community. Policy development may not sound like a very exciting task, but where it leads to more communication with and better support for academics I find it worthwhile and exciting enough.