In recent years, conversations about data governance have broadened beyond technical standards and infrastructure. Increasingly, researchers, institutions, and communities are asking deeper questions: Who does data serve? Who benefits? Who has authority over its use, especially when it concerns Indigenous Peoples?
As part of InternationalLove Data Week 2026, this blog post shares reflections on the CARE Principles, explains why they matter andexplores what more intentional practices around support for CARE principles might look like.
Open access publishing is sometimes mistakenly thought of as the be-all-and-end-all of open research (or open science). But while open access is important, it is not enough to capture the full breadth of research contributions, outputs and impacts. There are other indicators that can tell us more about the openness and quality of research than journal-related metrics do.
The research community is adopting more open research practices. After all, research is about more than just publishing the final outcome. It involves the processes that produce it. Measuring the open access level of publications gives a narrow insight about research. It should ideally cover other pillars – such as sharing data and code, embracing preprints, and adopting transparent research protocols – for reliable and high-quality research.
Measuring the level of open research adoption could provide valuable insight into how far the community has progressed on the path toward openness. It would also allow us to advocate what practices researchers can implement to make their work more reliable. Perhaps, most importantly, open research indicators can offer a better alternative to unfruitful – even unhealthy – metrics that have created a research culture of perverse incentives, like Journal Impact Factor and h-index. Measuring open research is not easy due to the unsystematic adoption of practices and their application on publications, such as not including code used for research or a dataset made available on request. Unlike open access, these practices are not yet fully mature. Researchers may also overlook making their open research activities visible, even when they may already be engaging in them. Therefore, understanding and demonstrating the extent of adoption is important for raising awareness and fostering broader engagement.
Measuring open research is hard, but PLOS proves it can be done
The academic publisher PLOS has been working on this challenging task of measuring open research principles. Partnering with DataSeer (an AI-based tool that checks manuscripts for identifiers of open practices), they have been releasing the comprehensive PLOS Open Science Indicators (OSI) dataset since late 2022 containing open research indicators, such as data availability/share, code availability/share, and preprint adoption.
The latest version of the OSI dataset has a total of 138,995 PLOS research articles published between 2018 and March 2025 (see here for their methodology). The 2025 OSI dataset expands on previous versions by including two new indicators: protocol-sharing and study (pre)registration. Previous versions only had data availability/sharing, code availability/sharing and preprint posting. In this blog, I analyse publications of Imperial College London within the OSI dataset. It aims to 1) understand the level of open research adoption at Imperial 2) outline a simple methodology that other institutions can easily implement for their own analyses.
Methods to identify Imperial research outputs in the OSI dataset
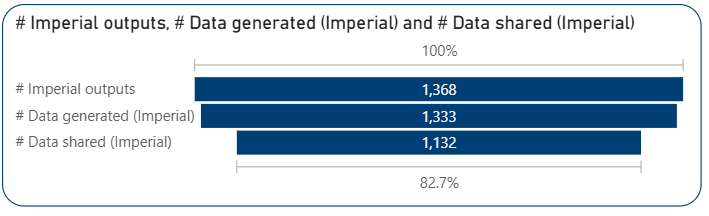
A simple methodology of matching research outputs of Imperial College London within the OSI dataset through DOIs is used. By using the internal Power BI report which is connected to Imperial’s current research information system, ‘journal article’ type items with a DOI published between 2018-2025 were downloaded (DOI is preferred as it allows matching outputs with a unique identifier). 1,368 out of 94,384 outputs matched the PLOS OSI dataset, representing 1.45% of Imperial’s total journal articles and accounting for nearly 1% of the entire PLOS dataset.
Figure 1: PLOS OSI dataset represents 1% of Imperial publications
Findings: open research practices at Imperial
97% of the Imperial articles have generated data. It is not surprising to see the high percentage of data-sharing (nearly 85% of articles that generated data) in Imperial outputs in the OSI dataset because of Imperial’s active data management policies and publisher/funder data availability requirements. Data sharing is nearly 9% higher among Imperial articles compared to the overall PLOS dataset.
Figure 2: Data sharing is the most adopted open research practice at Imperial (83% of journal articles published by Imperial authors from 2018 to 2025 included a link to shared data)
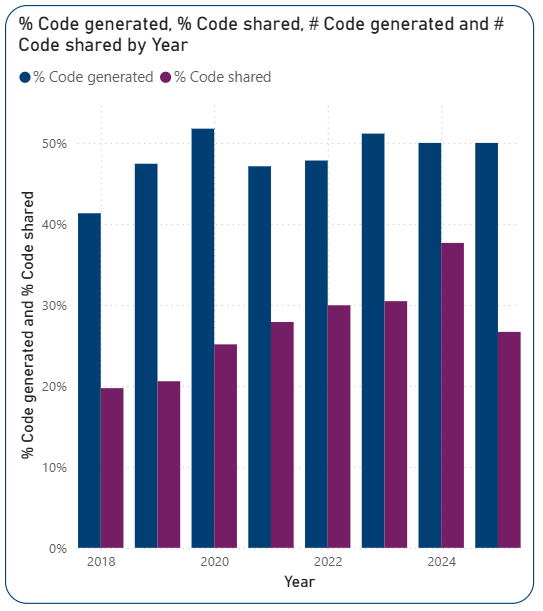
Accessing code which is the basis of research data generated within the output is vital for research integrity and reproducibility. Although there has been some improvement, codesharing isn’t as developed as data-sharing.
Nearly half of Imperial’s publications in the OSI dataset involved code generation. However, among those that did use code, only 56% have shared it, meaning that readers cannot ask the right questions about the reliability of the code underpinning the analysis in almost half the dataset.
Figure 3: The practice of sharing code in research outputs is increasing (2025 – incomplete year)
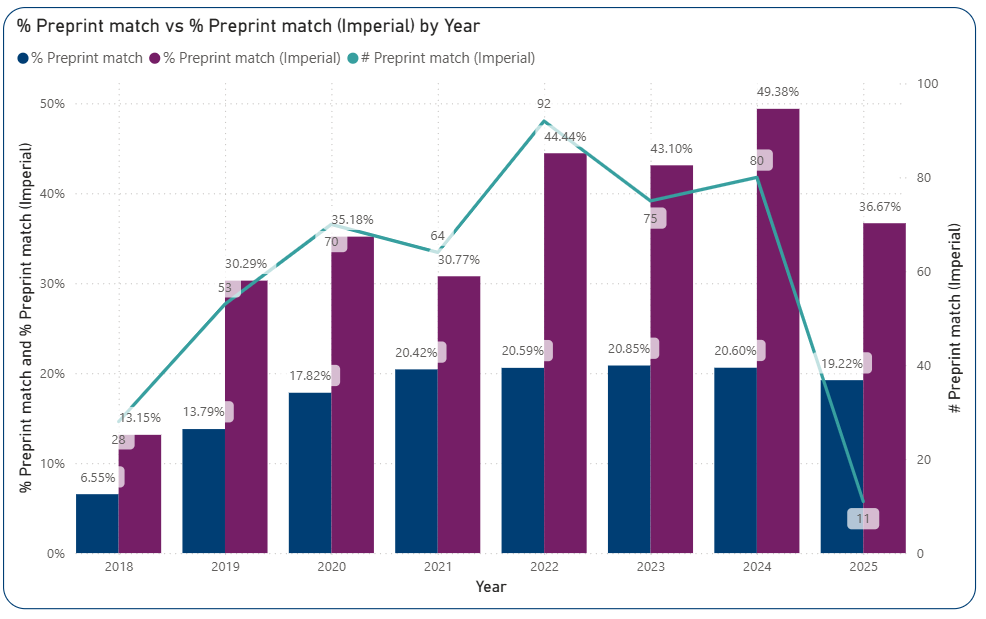
Posting preprints (non-peer-reviewed manuscripts posted to online servers before journal submission) has become a norm in many disciplines. Preprints improve research quality and increase visibility by enabling rapid dissemination and collaborative and timely feedback. It also a valuable indicator of bridge-building between research stages. Measuring how many publications originate from preprints can provide valuable insight into the adoption of open research practices. However, linking a preprint to its final published version can be challenging. The OSI dataset’s methodology promises to overcome this challenge.
35% of Imperial outputs in the PLOS dataset were associated with a preprint. Except for the incomplete year of 2025, preprint adoption has increased over recent years, jumping from 13% in 2018 to nearly 50% in 2024. The preprint match for Imperial publications is twice the global average in the PLOS set.
Figure 4: Preprint match of Imperial publications is higher than the global average
The latest version of the OSI dataset includes two new open research indicators: protocol and study registration. Although these two concepts have been incorporated in research process for some time, publishing and sharing them in outputs is relatively new. Implementing and sharing them is just as important as sharing data, as both are crucial for enhancing transparency and reproducibility, and ultimately for building trustworthiness in research.
Compared to other open research practices, the adoption of protocol sharing and study registration remains low. Only 10% of Imperial articles in the dataset included an available protocol and study registration, similar to the global average. The results here should be interpreted with caution since protocols are more common in certain fields than others.
Figure 5: Protocol sharing and study registration rank lowest among open research practices
Do open research practices reinforce one another? The answer is yes.
Given the comprehensiveness of the PLOS dataset, it would be interesting to look at the relationship between the open research indicators. When considering the outputs that shared data, the percentage of all other open research indicators increases (e.g. code sharing rises from 25% to 32%, preprint match from 35% to 38%). The change becomes even more noticeable when focusing on publications that shared code. Among the Imperial articles that shared code, data-sharing jumped from 83% to 98% and preprint matching increased from 35% to 59%. The same pattern is true for preprints: outputs matching a preprint are significantly superior in adopting other open research indicators, especially data and code sharing.
Figure 6: Outputs linked to preprints show higher adoption of other open research practices
Conclusion with reminding limitations and caveats
While the number of publications is significant, it only represents a tiny amount of the publication universe. The dataset includes open access outputs from one publisher that predominantly publishes in certain disciplines. Some fields, for instance, do not produce data as we understand it in the context of science. Also, preprinting may not be common where the journal article is not the main output type in some disciplines. It is also important to highlight that PLOS dataset puts journal articles in the centre and works backwards, meaning that we cannot confidently say whether open research practices were followed from the beginning of the research process or just at the time of publication. Generalising these conclusions to the entire research ecosystem without keeping the nuances in mind would be invalid and would risk creating gamification and perverse incentives in the same way that journal-based metrics have done for years. Despite its caveats, the PLOS Open Science Indicators dataset is a great starting point for measuring research in a more meaningful way, especially in the presence of unhealthy metrics. The analysis of the dataset gives us good insights into where we should focus our open research advocacy.
This brief analysis shows that while we seem to be in a strong position when it comes to sharing data, there is still room for improvement in other areas, such as sharing code, releasing preprints, making research protocols available, and registering studies before they begin, especially if they are underpinning elements of research. Everyone in this ecosystem, from researchers and institutions to funders and publishers, has a role to play in making this happen.
This post was written by Camille Regnault, Senior Scholarly Communications Assistant in the Research Data Management team.
Overview:
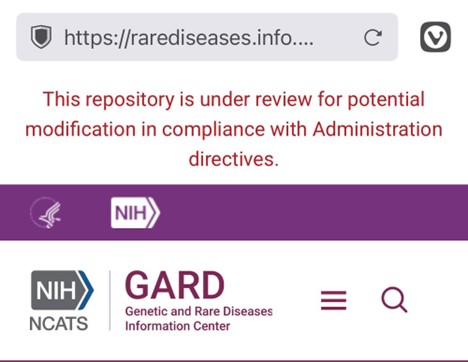
Earlier this year, several reports raised concerns about National Institutes of Health (NIH)-funded data repositories—critical to research and public health—being flagged for potential ‘review,’ prompting widespread unease within the scientific community.
These reports have emerged against a backdrop of sweeping grant terminations and cuts to research considered to be related to DEI programs, following Presidential Executive Orders in the US and a regime change under the NIH.
The NIH is the largest funder of biomedical research in the world and one of eleven divisions that fall under the US Department of Health and Human Services, making important discoveries that improve health and save lives. It is a key provider of resources such as PubMed and PubMed Central (PMC), for medical and health research as well as ClinicalTrials.gov, for clinical trial data.
In the wake of these major shakeups however, it has additionally become clear that access to a variety of federally-created and federally-hosted datasets has been limited or removed while access to others remains potentially at risk.
Data rescue efforts and stakeholder responses:
In February 2025, the Data Rescue projectemerged as the result of a coordinated effort between three data organisations, including members of IASSIST, RDAP, and the Data Curation Network, to attempt to safeguard threatened research data.
Their stated goal is ‘to serve as a clearinghouse for data rescue-related efforts and data access points for public US governmental data that are currently at risk’ and their efforts include ‘data gathering, data curation and cleaning, data cataloging, and providing sustained access and distribution of data assets’. You can read about their current efforts, here.
In the same month, the Harvard Law School Library Innovation Lab Team released the data.gov archive on Source Cooperative. The 16TB collection is available to access at https://source.coop/repositories/harvard-lil/gov-data/description and includes over 311,000 datasets harvested during 2024 and 2025. This is being updated on a daily basis as new datasets are added to data.gov.
In the UK members of the Chartered Institute of Library and Information Professionals (CILIP) Special Interest Groups, covering health and higher education, have identified concerning examples of removal and reduction of content relating to their work in public health, research, education, and science. Their recent statement invites members and the wider information profession community to share examples of how content, reports, datasets, evidence, and tools are being removed by US authorities.
What you can do:
If you’re an Imperial researcher or staff member affected by these changes, we strongly encourage you to reach out to the Research Data Management team. Your insights could help shape our response and contribute to broader sector-wide documentation efforts.
Stay informed by subscribing to the Data Rescue Project’s newsletter, which provides regular updates on the initiative’s progress. You can also explore opportunities to get involved and support their mission to safeguard vulnerable datasets here.
Additionally, if you’re a CILIP member or an information professional working within the UK sector, you can help assess the impact by completing a short form. Share examples of affected content, datasets, tools, or evidence to aid in understanding the scale and implications of these changes across the UK.
This post is authored by Yusuf Ozkan, Research Outputs Analyst, and Dr Hamid Khan, Open Research Manager: Academic Engagement.
Researchers increasingly use social media to communicate their research. They share links to journal articles, but also other types of output like preprints, graphics/figures and lay summaries.
That enables us to measure alternative indicators of research visibility beyond citations of, and in, journal articles. With many services like X, Mastodon, Threads and LinkedIn, researchers and the public are scattered across the social media world, which makes tracking visibility difficult. Bluesky has joined the club recently and is growing rapidly. In this post, we highlight how research-related conversations and citations of Imperial outputs have increased on Bluesky, emphasising the value of using the Library’s tools to track citations on social media.
Although Bluesky is a relatively new platform – launched in 2023 as an invitation-only service – it has reached nearly 30 million users at the time of writing. The number of users increased by seven million in just six weeks from November 2024.
Given the increase in users, we would expect to see research outputs being shared more widely on Bluesky. But it is extremely difficult, if not impossible, to manually measure that. This is where Altmetric comes into play, to track mentions of outputs.
Altmetric is a tool for providing data about online attention to research by identifying mentions of research outputs on social media, blog sites, Wikipedia, news outlets and more. Altmetric donuts and badges display an attention score summarising all the online engagement with a scholarly publication. Altmetric can be useful to show societal visibility and impact, though its limitations should also be kept in mind. Imperial Library has a subscription to Altmetric. We can use Altmetric to see how social media users interact with Imperial’s research outputs. It’s one of many tools we use to support researchers to move away from journal-based metrics for evaluating the reach of their work.
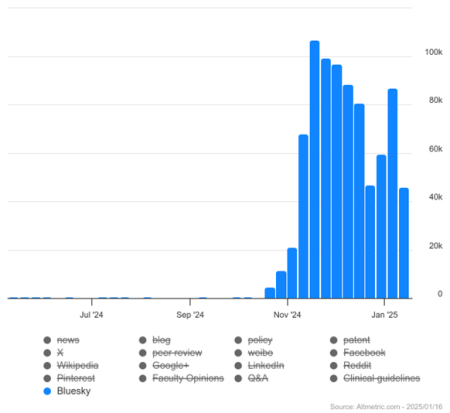
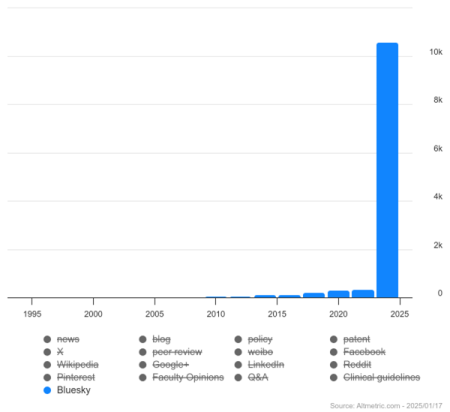
The migration of researchers away from X prompted Altmetric to start to monitor emerging platforms, leading to the inclusion of Bluesky in Altmetric statistics in December 2024, although the platform had been picking up citations on Bluesky since October.
There are nearly 400 thousand Bluesky posts citing a research paper from late October to mid-January – less than just three months, which is a significant milestone considering it took Twitter nine years to reach 300 thousand posts linking a research paper.
Altmetric picked up a dramatic global increase in mentions of research outputs on Bluesky from November 2024
Bluesky is a rising star for research conversations online, but what is the situation when it comes to mentions of Imperial research outputs? Well, the trend is no different from the overall picture.
Altmetric identifies over 11,000 mentions of publications on Bluesky associated with Imperial authors from November 2024 to January 2025. The number of Imperial output mentions on X is four times higher than Bluesky for the same period. Given that Bluesky has been launched recently and has ten times fewer users than X, the figure is still substantial.
Bluesky is the second-most-referenced source type after X for research outputs tracked by Altmetric, November 2024 – January 2025.
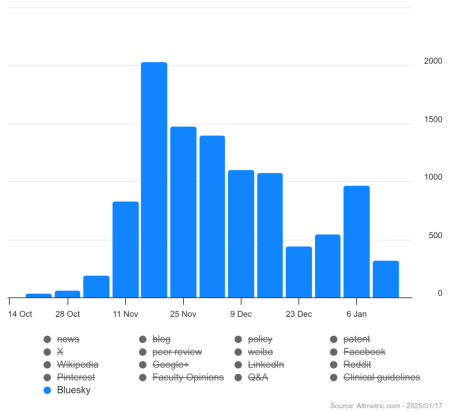
The mentions of Imperial publications on Bluesky followed a similar trend to the overall mentions of research outputs on the platform. There was a massive uptick in mid-November 2024, taking the number from a few mentions to thousands per week. Although the number of mentions appears to be coming down, the increasing number of overall Bluesky users and posts suggests citations are not likely to return to their pre-November level.
Massive uptick in mentions of Imperial publications on Bluesky from mid-November 2024
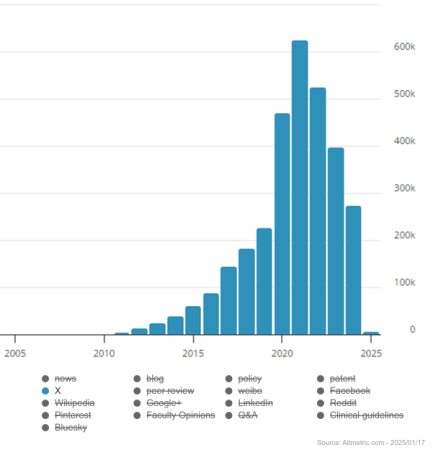
Comparing mentions on Bluesky with X for all time gives us another perspective on how sharing practices have changed. The number of X mentions for Imperial outputs has consistently decreased since 2021 from 620K mentions to 270K in 2024. If this trend continues, we expect to see just over 100K mentions in 2025.
Mentions of Imperial research outputs on X peaked in 2021 and have plummeted ever since
Even though Bluesky is just two years old and Altmetric have been including mentions on the platform for three months, the volume of mentions is impressive.
Bluesky is a new social media platform whose users are increasing. The volume of research-related conversation on Bluesky has increased since October 2024, making it the second-largest data source tracked by Altmetric over the past three months. Imperial research outputs are widely shared on the platform, too, with the citation of over 10K for the same period. But there is a note of caution.
Social media is great for increasing visibility and reach. It can be a good way to encourage open and collaborative peer review, and ultimately help improve quality and impact. However, metrics provided by platforms like Altmetric can be misleading, as they don’t track everything happening on the internet. For example, Altmetric only includes historical data for LinkedIn. Current mentions are not tracked despite the presence of many researchers on LinkedIn.
Social media platforms have some biases, such as vulnerability to manipulation and gaming (just like the Journal Impact Factor), imbalanced user demographics, and either over- or under-representation of an academic discipline on one platform. Counting citations is a risky business, because social media mentions do not necessarily point to positive impact or high quality. Someone could be critiquing or rebutting your work in citing it. Despite limitations, diverse platforms for sharing research are good for discoverability, since one user of a platform may not use another. This increases the potential impact of research by reaching diverse audiences. Bluesky is a recent and promising example, demonstrating how emerging platforms can broaden the reach and visibility of research publications.
To see how your research is being seen and cited on social media, you can make use of the Library’s subscription to Altmetric. Get in touch with the Bibliometrics service to discuss ways to measure the visibility and impact of your work other than the flawed Journal Impact Factor.
Note: This post was authored in mid-January. Therefore, some of the figures might have changed by the time of publication.
As part of #LoveData24, the Research Data Management team had a chance to catch up with Yves-Alexandre, Associate Professor of Applied Mathematics and Computer Science at Imperial College London, who also heads the Computational Privacy Group (CPG). The CPG are a young research group at Imperial College London studying the privacy risks arising from large scale behavioural datasets. In this short interview we discussed the interests of the group, the challenges of managing sensitive research data and whether we need to reevaluate what we think we know about anonymisation.
How did you become involved with the Computational Privacy Group (CPG)?
Yves-Alexandre de Montjoye (YD)
So, my career as a researcher started when I was actually doing my master’s thesis at the Santa Fe Institute in New Mexico. That was in in 2009. This was pre-A.I. and the beginning of the Big Data era. People were extremely excited about the potential for working with large amounts of data to revolutionise the sciences, ranging from social science to psychology, to urban analytics or urban studies and medicine.
So many things suddenly became possible and people were like, ”this is the microscope”, or any other kind of analogy you can think of in terms of this being a true revolution for the scientific process. Some even went as far as saying, “this is the end of theory, right?” or “this spells the end of hypothesis testing. The data are going to basically speak for themselves”. There was a huge hype of expectation which, as time went on gradually decreased and eventually plateaued to what it is now. It did have a transformative impact on the sciences but to me it became quite obvious working with these data as a student, just how reidentifiable all these types of data potentially were.
Back in the days, we were looking at location data across the country and on the one hand, everyone was talking about how the data were anonymous. As a student, I was working with the data and I could see people moving around on the map, so to speak. And it just blew my mind. It didn’t seem like it would take very much for these data to not be anonymous anymore.
Anonymisation and the way we’ve been using it to protect data have been well documented in the literature. There has also been extensive research on how to properly anonymise data. I think what has taken a bit of time for people to grasp is that anonymisation, in the context of big data, is its own new, different question, and that actually a lot of the techniques that had developed from around 1990 to 2010 were basically not applicable to the world of big data anymore.
This is mostly due to two factors. The first one is just the sheer amount of data that is being collected about every single person in any given dataset that we are interested in, from social science to medicine.
Combining these with social media and the availability of auxiliary data (meaning data from an external source, such as census data) means that not only are there a lot of data about you in those datasets, but there are also a lot of data about you that can be cross-referenced with sources elsewhere to reidentify you. And I think what took us quite a bit of time to get across to people was that this was a novel and unique issue that had to be addressed. It’s really about big data and the availability of auxiliary data. I think that’s really what led a lot of our research into privacy. Regarding anonymisation, we are interested in the conversation around whether there is still a way to make it work as intended given everything we know or do we need to invent something fundamentally new. If that is the case, what should our contribution to a new method look like?
At the end of the day, I think the main message that we have is that anonymisation is a powerful guarantee because it is basically a type of promise that is made to you that the data are going be used as part of statistical models, et cetera, but they’re never going to be linked back to you.
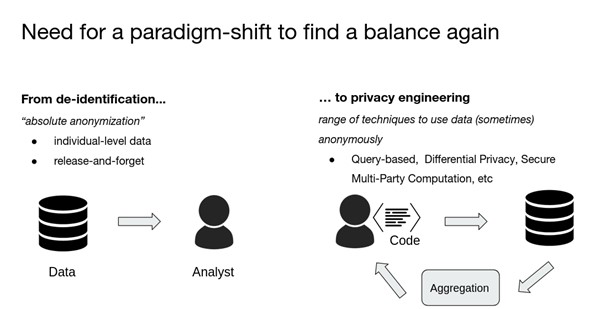
The challenge lies in the way we go about achieving this in practice. Deidentification techniques and principles such as K-anonymity are (unfortunately) often considered a good way of protecting privacy. These techniques which, basically take a given dataset and modify it in one way or another, might have been considered robust enough when they were invented in the 90s and 2000s, but because of the world we live in today and the amount of data available about every single person in those datasets, they basically fall short.
There is a need for a real paradigm shift in terms of what we are using and there are a lot of good techniques out there. Fundamentally, the question comes down to what is necessary for you to make sure that the promise of anonymisation holds true, now and in the future.
Yves-Alexandre de Montjoye
Could you talk to me a little bit about the Observatory of Anonymity and what this project set out to achieve? And then as a second part of that question, are there any new projects that you’re currently working on?
YD: The Observatory of Anonymity comes from a research project published by a former postdoc of mine, and the idea is basically to demonstrate with very specific examples to people, how little it takes to potentially reidentify someone.
Fundamentally, you could spend time trying to write down the math to make sense of why you know for a certain number of reasons that a handful of pieces of information are going to be sufficient in linking back to you. The other option is to look at an actual model of the population of the UK. As a starting point, we know that there are roughly 66 million people living across the country. Even if you take London, there are still 10 million of us. And yet, as you start to focus on a handful of characteristics, you begin to realise very quickly, that those characteristics, when put together, are going to make you stand out and a significant fraction of the time that can mean that you will be the only person in all of the country to match those sets of characteristics.
The interesting part is what do we do?
You’re working within Research Data Management and your team are increasingly dealing with sensitive data and the question of how they can be safely shared?
Clearly there are huge benefits to data being shared in science, in terms of verifying research findings and reproducing the results and so on. The question is how do we go about this? What meaningful measures can you put in place to ensure that you sufficiently lower the risks of harmful disclosure in such a way that you know that the benefit of showing these data will clearly outweigh those risks?
I think from our perspective, it’s really about focusing on supporting modern privacy-ensuring approaches that are fit for purpose. We know that there are a range of techniques; from controlled access to query-based systems, to some of the encryption techniques that, depending on the use case, who needs to access your data, and the size of your dataset would allow someone to use your data, run analysis, and replicate your results fully without endangering people’s privacy. For us, it’s about recognising the right combination of those approaches and how we develop some of these tools and test them.
I think there has been a big push towards open data, under the de-identification model, for very good reasons. But this should continue to be informed by considerations around appropriate modern tools, to safeguard data while preserving some utility. Legally at least, you cannot not care about privacy and if you want to care about privacy properly, this will affect the utility. So we need to continue to handle questions around data sharing on a case-by-case basis rather than imply that everything should be fully open all of the time. Otherwise this will be damaging to the sciences and to privacy.
Yes, it is important to acknowledge that that tension between privacy and utility of research data exists and that a careful balance needs to be struck but this may not always be possible to achieve. This is something that we try to communicate in our training and advocacy work within Research Data Management services. We have adopted a message that can hopefully be helpful (and which originated from Horizon Europe[1]), which states that open science operates on the principle of being ‘as open as possible, as closed as necessary’. In practice this means that results and data may be kept closed if making them open access is against the researcher’s legitimate interests or obligations to personal data protection. This is where a mechanism such as controlled access could play a role.
YD: Just so. I think you guys have quite a unique role to play. A controlled access mechanism that allows a researcher to run some code on someone else’s data without seeing the data on the other hand requires systems of management, authorisation and verification of users, et cetera. This is simply out of the reach of many individual researchers. As a facility or as a form of infrastructure however, this is actually something that isn’t too difficult to provide.
I think France has something called the CASD, which is the Center for Secure Access to Data (or Centre d’Accès Sécurisé aux Données) and this is how the National Institute of Statistics and Economic Studies (INSEE) is able to share a lot of sensitive data. Oxford’s OpenSAFELY in the UK is another great example of this. They are ahead in this regard. We need similar mechanisms when it comes to research data to facilitate replicability, reuse and for validating and verifying results. It is absolutely necessary. But we need proper tools to do this and it’s something that we need to tackle as a collective. No individual researcher can do this alone.
What in your experience are common misconceptions around anonymisation in the context of research data?
YD: I think the most common misunderstanding is a general underestimation of the scale of data already available. Concerns often revolve around a notion of, could someone search another person’s social media and deduce a piece of information to reidentify them in my medical dataset? In the world of big data, I would argue that what we strive to protect against also includes far stronger threat models than this.
We had examples in the US in which you had right wing organisations with significant resources buying access to location data, matching them manually, potentially at scale with the travel record, and other pieces of information they could find about clerics to potentially identify them in this dataset, in an attempt to see if anyone was attending a particular seminar[2].
We had the same with Trump’s tax record. Everyone was searching for the tax record and it turns out that it was available as part of an ’anonymous’ dataset, made available by the IRS and again these were data that were released years and years ago.
They remained online and then suddenly they’re an extremely sensitive set of information that you can no longer meaningfully protect.
This goes back to what you were saying again about anticipating how certain techniques could be used in the future to potentially exploit these data.
YD: Actually, on this precise point, we know from cryptography that good cryptographic solutions are actually fully open and that the cryptographic solution is solid. I can describe to you the entire algorithm. I can give you the exact source code. The secrecy is protected by the process but the process itself is fully open.
If the security depends on the secrecy of your process, often you’re in trouble, right? And so a good solution actually doesn’t rely on you hiding something, something being secret, or you hoping that someone is not going to figure something out. And I think that this is another very important aspect.
And this perhaps goes back again, to the type of general misunderstandings which sometimes arise where someone might assume that because some data have to be kept private, as you were saying, that the documentation behind the process of ensuring that security also has to be kept private, when in fact you need open community standards that can be scrutinised and that people can build upon and improve. This is very relevant to our work in supporting things like data management plans, which require clear documentation.
We have reached our final question: There is arguably a tendency to focus on data horror stories to communicate the limitations of anonymisation (if applied for example without a proportionate risk-based approach for a research project). Are there positive messages we can promote when it comes to engaging with good or sensible practice more broadly?
YD: In addition to being transparent about developing and following best practices as we have just talked about, I think there needs to be more conversations around infrastructure. To me, it is not about someone coming up with and deploying a better algorithm.
We very much need to be part of an infrastructure building community that works together to instill good governance.
There are plenty of examples already in existence. We worked, for example, a lot on a project called Opal which is a great use case of how we can safely share very sensitive data for good. I think OpenSAFELY is another really good case study from Oxford and the CASD in in France as I already mentioned.
These case studies offer very pragmatic solutions, but are an order of magnitude better, both from the privacy and the utility side, than any existing legacy solutions that I know of.
This post was written by Ruth Harrison, Head of Scholarly Communications Management at Imperial College London.
After many years of work, the College will soon be able to announce that we are updating our institutional open access policy to allow researchers to make their peer-reviewed journal articles and conference proceedings available on open access under a CC BY licence at the point of publication with no embargo. This will apply to accepted manuscripts, and enable staff and students to retain their right to reuse the content of those outputs in teaching, research and further sharing of their work.
Why?
I don’t think many people would disagree with the moral and ethical case for open access to research, and that the principles of open research should be more widely applied. This is a global endeavour – in 2022, UNESCO published its recommendation on Open Science stating:
“By promoting science that is more accessible, inclusive and transparent, open science furthers the right of everyone to share in scientific advancement and its benefits as stated in Article 27.1 of the Universal Declaration of Human Rights.”
Open access publishing has existed for more than two decades now, and in the past 10 years, funders have increasingly required open access to the published outputs of research which public money, ultimately, has enabled. In the UK (and internationally) this has resulted in various policies which researchers, libraries and publishers have had to keep track of, and there are now many models through which open access can be achieved. But this also means considerable ‘policy stack’ and confusion, with varying workflows and messaging for researchers to keep up with.
Introducing a policy through which author rights to their accepted manuscript are retained is a solution to the policy stack. Based on the lead taken by MIT with their open access policy, introduced over a decade ago, and other institutions around the world, within the UK the case has been made that we should adopt the same approach. At Imperial, this began with the introduction of the concept of the UK-SCL – Scholarly Communications Licence – and has now developed into what will be our Research Publications Open Access Policy (RPOAP). Generally such policies are referred to as rights retention policies or strategies, and we will join over 20 other UK universities who have already implemented similar policies, including the universities of Edinburgh, Cambridge, Oxford and Glasgow, as well as Sheffield Hallam, Swansea, Queen’s University Belfast and the N8 institutions.
How does a rights retention policy work?
There are some key points to make:
Authors will retain copyright over their work
Under the policy, each author grants the College a non‐exclusive, irrevocable, sub-licensable, worldwide licence (effective from acceptance of publication) to make the AAM author accepted manuscript publicly available under the terms of a Creative Commons Attribution (CC BY) licence
The right being granted is that of allowing the College to make the accepted manuscript openly available in Spiral without an embargo
The College does not retain the copyright to research outputs – that is waived in favour of academics
The policy applies to peer-reviewed journal articles and conference proceedings
There is no restriction on choosing where to publish.
For the policy to be effectively implemented:
Publishers need to be informed when an institution is going to implement a rights retention policy
On behalf of all staff and students, the College will notify publishers of the policy
There will be a list available of notified publishers.
What will authors need to do?
Authors should continue to upload their accepted manuscripts to Symplectic Elements which means for many people, there will be no change in their workflow at acceptance. When an accepted manuscript is received, the Library Services open access team will process it including managing any accompanying APC (article processing charge) application.
We would recommend that authors:
familiarise themselves with the RPOAP when it is published
consult the list of notified publishers when they are preparing a manuscript for submission – this will be available in the next few weeks
use our publisher agreements search tool to find out if the Library Services has covered the cost of open access publishing for the version of record
upload their accepted manuscripts (or a link to where a copy is already deposited, such as arXiv or another institutional repository) as soon as they can after acceptance
What’s next?
When the policy implementation date is agreed by University Management Board, there will be further communications across College, contact information and guidance available online at the Scholarly Communication website. This will include the list of notified publishers, and advice on what to do if your intended publisher is not on that list. And it is not only staff who will be able to take advantage of the policy, students are included as well – if you are a student publishing a journal article or conference paper, you will grant and retain the same rights as outlined above.
In the spirit of this year’s International Open Access Week theme, Community over Commercialisation, the ultimate question is: who decides? Should publishers get to decide what research readers see and what they can do with it, or should it be for the research community to decide for itself? RPOAP answers the question in favour of the community.
We have a new tool available that allows you to search for journals that are included in publisher open access agreements for Imperial College London-affiliated corresponding authors. You can search by journal title, ISSN, or enter a keyword and be provided with a list of journal titles containing that word.
The tool (powered by SciFree) is part of our revamped publisher agreements and discounts webpage, which has also been reformatted for ease of navigation as the number of agreements Imperial is part of has grown. A full list of journals with fully covered APCs (.xls) is also available from the webpage to view in an Excel spreadsheet (Imperial members only).
The search tool allows users to see whether titles are included in agreements that fully cover the open access fee, offer a discount, or whether they are not covered but you can apply to the Imperial Open Access Fund (see the three examples below). Each of these icons links to instructions or further information for the relevant option.
The results also give the default open access license for the journal, and whether it is a fully open access journal, or hybrid (a subscription journal offering an open access option).
Also featured are links to the Directory of Open Access Journals (DOAJ), and an embedded version of the Plan S Journal Checker Tool (JCT). Journals listed in DOAJ are eligible for the Imperial Open Access Fund, so if your chosen journal is not part of a publisher agreement, but is listed in DOAJ, you should apply to the Imperial Fund. (Eligibility also requires that you have no access to alternative funding for open access, and that the paper is a research article). The Plan S JCT allows authors with UKRI or Wellcome Trust funding to check their options for meeting their funder’s open access requirements. Contact the open access team at openaccess@imperial.ac.uk if you need any help interpreting the search results.
If you want to feed back on whether this search tool was helpful, or access a link to book a one-to-one training session with the open access team, you can use the chat icon at the bottom right of the page. You can also book a training session via our website, or email us at openaccess@imperial.ac.uk
As was highlighted by Imperial’s Director of Library Services Chris Banks in her blog post earlier in this International Open Access Week 2022, the past few years have seen a rapid increase in the number of publisher agreements that Imperial College has signed up to. We now have 33 agreements in place that allow for open access (OA) fees to be fully covered for corresponding authors affiliated with imperial College London at no further cost.
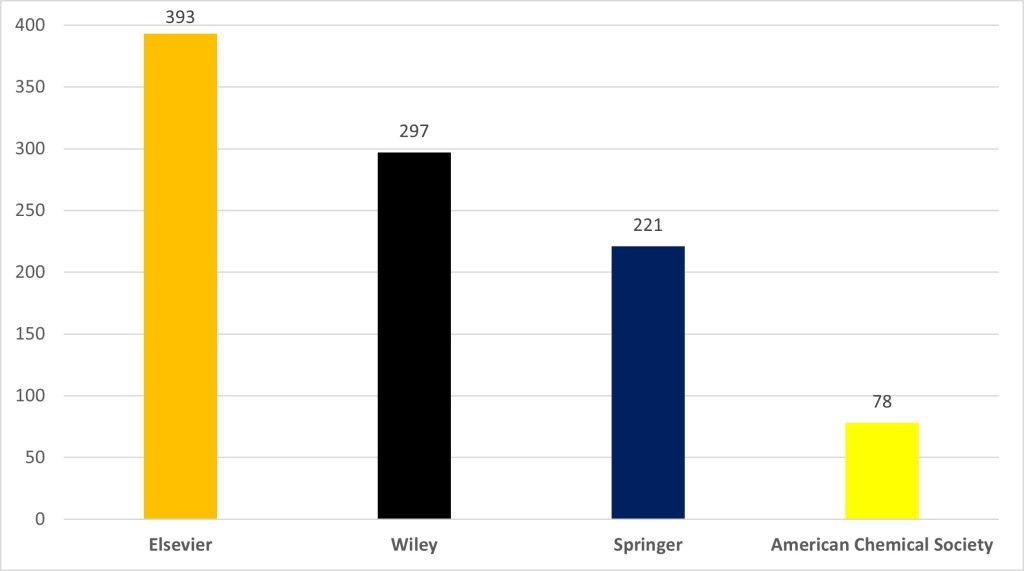
This has unsurprisingly led to a significant increase in the number of papers being made OA through such agreements. The below graph shows the number of papers covered over the last year via four of the most used Read & Publish agreements that we currently have:
Imperial papers made OA through publisher agreements (1 Oct 2021 – 30 Sep 2022)
This adds up to almost 1000 OA papers from these four agreements alone, which does not include the figures from other publishers we have agreements with such as SAGE, Oxford University Press, Taylor & Francis, and Cambridge University Press.
A shift away from individual APC payments?
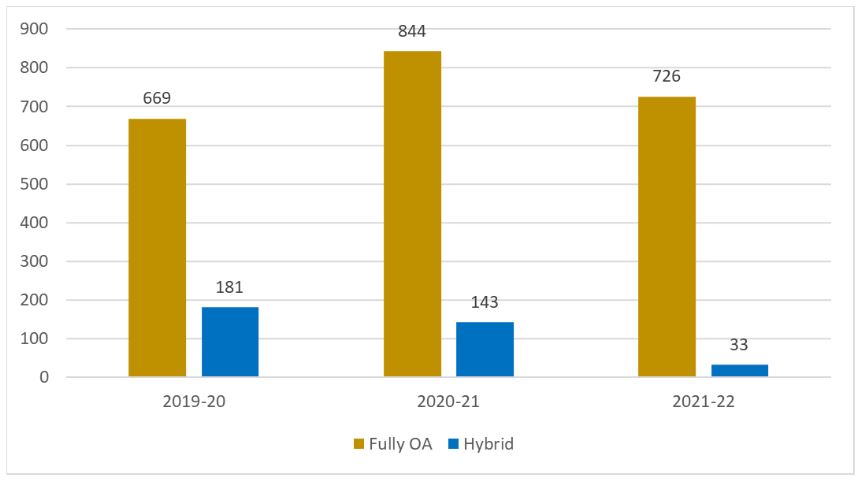
As was predicted in an earlier blog post from OA Week 2020, the number of papers now being covered through publisher agreements has now overtaken the number of individual Article Processing Charges (APCs) that we pay for from the OA funds that we administer. For the period from 1 October 2021 to 30 September 2022 we paid for a total of 759 APCs, compared to well over 1000 covered through the agreements.
While we have only seen a slight drop in the total number of individual APCs paid for compared to last year, the most significant change has been an ongoing reduction in the number of APCs we have paid for papers in hybrid journals specifically (i.e. subscription journals that have an OA option) as shown in the below graph:
Individual APCs paid for from OA funds
This reduction in individual payments for APCs in hybrid journals should not be attributed to the increase in publisher agreements alone, as changes to funder policies in recent years have also introduced tighter restrictions on hybrid APC payments, and have offered authors alternative routes to compliance via the green OA route through rights retention. However, it is certainly one of the main reasons behind this shift and is a desired outcome in the transition away from a publishing model that allowed for ‘double-dipping’.
Imperial Open Access Fund
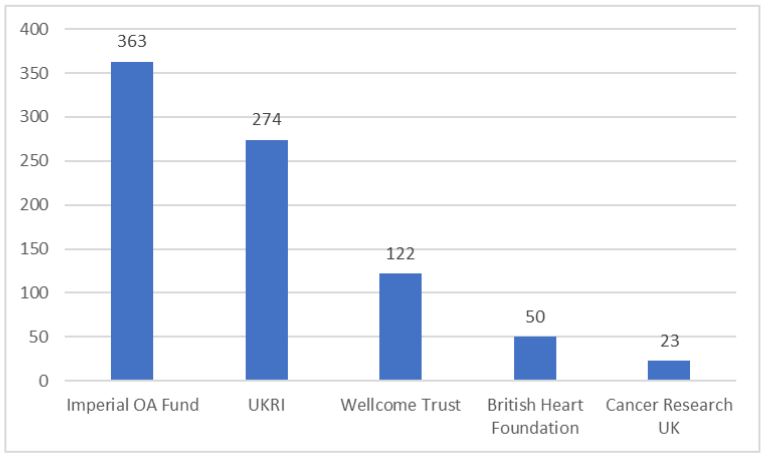
As most publisher agreements do not require authors to be funded, they have allowed many papers to be made OA via the gold route that would otherwise not have been eligible. As well as our funder OA block grants, we are also fortunate to be able to offer our authors the Imperial Open Access Fund. This is available for those without alternative funds available, and can be used to pay APCs for original research papers in fully OA journals listed in the Directory of Open Access Journals.
Although some of our publisher agreements do cover fully OA as well as hybrid journals (e.g. Wiley’s), most of them do not, and there are many publishers who exclusively offer fully OA journals with compulsory APCs. This means the Imperial OA Fund continues to have a big part to play in enabling our authors to publish OA and covered 363 APCs in the last year (nearly half of the total amount):
APCs paid for by each fund (1 Oct 2021 – 30 Sep 2022)
For details on Imperial’s current publisher agreements, please see our newly revamped Publisher agreements and discounts page, and for details on our OA funds and how Imperial authors can apply for APC funding please see our Applying for funding page.
UK higher education institutions along with Jisc are currently in negotiation for a new “read and publish” agreement (also referred to as “transitional” or “transformative” agreements) with the publisher Springer Nature. Our current agreement runs to the end of December 2022 and we are seeking a new agreement that will not only enable us to read the journals covered by the deal, but also enables researchers to publish open access in those journals at no additional cost.
The sector has agreed criteria for our negotiations. Agreements should
Reduce and constrain costs
Provide full and immediate open access publishing
Aid compliance with funder open access requirements
Be transparent, fair, and reasonable
Deliver improvements in service, workflows, and discovery
We achieved these aims with last year’s negotiations with Elsevier and are seeking to do so with Springer Nature. In addition to seeking a renewal of the existing Springer Compact agreement which has been running since 2016, we are also seeking to include Nature research journals and Palgrave journals.
If you are reading this and wondering what a “transitional” agreement is, my colleague David Phillips wrote about these in an earlier blog. At the time David noted that we had 11 such agreements in place at Imperial. This has now risen to 33 with fully covered publishing costs plus further agreements which include discounted article processing charges (APCs). Back in 2019, only 9% of sector spend enabled full OA publishing. That figure is now over 80%.
Why are the negotiations criteria important for researchers?
It is worth taking a moment to reflect on the sector criteria and what they mean for academic authors:
Reduce and constrain costs
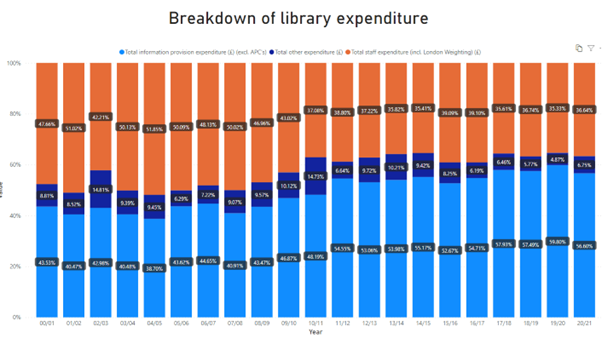
To be sustainable, the costs of reading and publishing cannot continue rising more than that of inflation. Back at the turn of the century, under 44% of Imperial’s Library Services budget was spent on content. Today it is closer to 60% and further increases are simply not sustainable either for Imperial or for the sector. Our most recent Jisc negotiations went some way to stem the rise and we need the agreement with Springer Nature to similarly deliver. To illustrate the impact of increasing content prices, the chart below shows the breakdown of expenditure on staff, operations, and content costs.
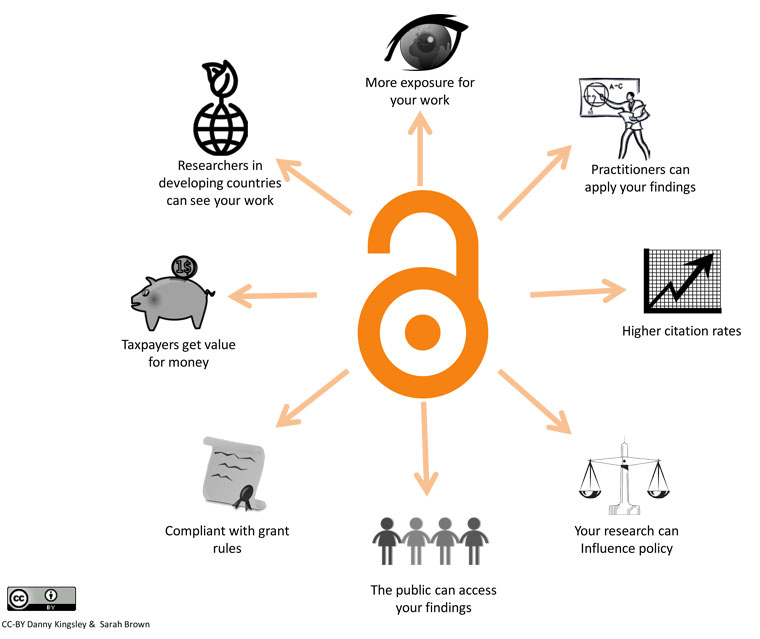
Provide full and immediate open access publishing
Jisc have a very helpful webpage detailing the benefits of open access publishing and from which this illustration is sourced:
Aid compliance with funder open access requirements
One of the questions that libraries frequently get asked is what should authors do to both ensure they meet funder obligations, and that their research outputs are eligible for the Research Excellence Framework – the REF. Our agreement with Springer Nature needs to enable both, affordably.
Be transparent, fair, and reasonable
As researchers you have secured the grant funding, you have assembled the team, drawn up the protocols, undertaken the research, undertaken the analysis and written up the findings. You then undertake the peer review. All of the above without payment from the publisher. You may also act as editors for journals, often on a voluntary basis with no compensation. Libraries then pay the publisher for publishing and content provision services. We need those payments to be transparent, fair and reasonable, reflecting the contribution researchers already make to the system.
Deliver improvements in service, workflows, and discovery
We are in a transition from paying for content to paying for publishing services on behalf of researchers. It is really important that those services are efficient for all parties otherwise we simply introduce additional administrative costs into the system. For authors, time spent battling a clunky submissions system or an unclear or conflicting publishing contract, especially processes which involve back and forth with libraries, are taking time away from your research activities as well as adding to admin burdens.
It is of course vital that research is discoverable for it to be built on and to have impact.
Researchers can continue to publish in SN journals and meet both funder OA obligations and have REF eligibility
The UKRI Open Access Policy which came into force in April 2022 is accompanied by a FAQ which includes the following statement:
“It is the intention that the UK higher education funding bodies will consider a UKRI open access compliant publication to meet any future national research assessment open access policy without additional action from the author and/or institution”
To be sure that your research output both meets funder requirements and is eligible for the next REF, we advise that you insert the following Rights Assertion Statement on all submitted articles (not just Springer Nature):
“For the purpose of open access, the author has applied a ‘Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising”
About me: I am Director of Library Services at Imperial College London. My profile is here and you can find me on twitter @ChrisBanks. I have an ORCiD and you can get yours here
This year’s International Open Access Week takes place from 24–30 October, and the theme is Open For Climate Justice.
This year’s theme seeks to encourage connection and collaboration among the climate movement and the international open community. Sharing knowledge is a human right, and tackling the climate crisis requires the rapid exchange of knowledge across geographic, economic, and disciplinary boundaries.
12 Month Highlights
At Imperial College London, we provide advice and guidance on an ever more rapidly changing open access landscape. The last 12 months have seen:
the successful results of our REF 2021 submission. A significant proportion of published research was made available on open access as a result of the 2018 REF OA policy to deposit the manuscript within 3 months of acceptance into a repository.
the start of a new UKRI open access policy from 1 April 2022 which requires immediate open access, without any embargo, under an open licence which applies to peer-reviewed research articles submitted for publication on or after 1 April 2022. We created a UKRI Open Access Policy YouTube video to explain the workflow.
the start of a new NIHR open access policy from 1 April 2022 which requires immediate open access, without any embargo under, an open licence which applies to peer-reviewed research articles submitted for publication on or after 1 April 2022
for published research that is funded by UKRI, Wellcome Trust, NIHR, and Horizon Europe a new Rights Retention Statement requirement on submissions “For the purpose of open access, the author has applied a Creative Commons Attribution (CC BY) license to any Author Accepted Manuscript version arising”
the increase to 33 of new publisher agreements and discounts, many of which cover open access fees in full for Imperial corresponding authors. This includes a three-year agreement with Elsevier the largest publisher of Imperial research
the Library’s support for several publishing initiatives within Jisc’s open access community framework (OACF) 2022-24 which aims to provide financial support for innovative open access content models
our first ever training session for all researchers new to Imperial covering open access and research data management (RDM)




 We have a new tool available that allows you to search for journals that are included in publisher open access agreements for Imperial College London-affiliated corresponding authors. You can search by journal title,
We have a new tool available that allows you to search for journals that are included in publisher open access agreements for Imperial College London-affiliated corresponding authors. You can search by journal title,