This post was written by Camille Regnault, Senior Scholarly Communications Assistant in the Research Data Management team.
Overview:
Earlier this year, several reports raised concerns about National Institutes of Health (NIH)-funded data repositories—critical to research and public health—being flagged for potential ‘review,’ prompting widespread unease within the scientific community.
These reports have emerged against a backdrop of sweeping grant terminations and cuts to research considered to be related to DEI programs, following Presidential Executive Orders in the US and a regime change under the NIH.
The NIH is the largest funder of biomedical research in the world and one of eleven divisions that fall under the US Department of Health and Human Services, making important discoveries that improve health and save lives. It is a key provider of resources such as PubMed and PubMed Central (PMC), for medical and health research as well as ClinicalTrials.gov, for clinical trial data.
In the wake of these major shakeups however, it has additionally become clear that access to a variety of federally-created and federally-hosted datasets has been limited or removed while access to others remains potentially at risk.
Data rescue efforts and stakeholder responses:
In February 2025, the Data Rescue projectemerged as the result of a coordinated effort between three data organisations, including members of IASSIST, RDAP, and the Data Curation Network, to attempt to safeguard threatened research data.
Their stated goal is ‘to serve as a clearinghouse for data rescue-related efforts and data access points for public US governmental data that are currently at risk’ and their efforts include ‘data gathering, data curation and cleaning, data cataloging, and providing sustained access and distribution of data assets’. You can read about their current efforts, here.
In the same month, the Harvard Law School Library Innovation Lab Team released the data.gov archive on Source Cooperative. The 16TB collection is available to access at https://source.coop/repositories/harvard-lil/gov-data/description and includes over 311,000 datasets harvested during 2024 and 2025. This is being updated on a daily basis as new datasets are added to data.gov.
In the UK members of the Chartered Institute of Library and Information Professionals (CILIP) Special Interest Groups, covering health and higher education, have identified concerning examples of removal and reduction of content relating to their work in public health, research, education, and science. Their recent statement invites members and the wider information profession community to share examples of how content, reports, datasets, evidence, and tools are being removed by US authorities.
What you can do:
If you’re an Imperial researcher or staff member affected by these changes, we strongly encourage you to reach out to the Research Data Management team. Your insights could help shape our response and contribute to broader sector-wide documentation efforts.
Stay informed by subscribing to the Data Rescue Project’s newsletter, which provides regular updates on the initiative’s progress. You can also explore opportunities to get involved and support their mission to safeguard vulnerable datasets here.
Additionally, if you’re a CILIP member or an information professional working within the UK sector, you can help assess the impact by completing a short form. Share examples of affected content, datasets, tools, or evidence to aid in understanding the scale and implications of these changes across the UK.
As part of #LoveData24, the Research Data Management team had a chance to catch up with Yves-Alexandre, Associate Professor of Applied Mathematics and Computer Science at Imperial College London, who also heads the Computational Privacy Group (CPG). The CPG are a young research group at Imperial College London studying the privacy risks arising from large scale behavioural datasets. In this short interview we discussed the interests of the group, the challenges of managing sensitive research data and whether we need to reevaluate what we think we know about anonymisation.
How did you become involved with the Computational Privacy Group (CPG)?
Yves-Alexandre de Montjoye (YD)
So, my career as a researcher started when I was actually doing my master’s thesis at the Santa Fe Institute in New Mexico. That was in in 2009. This was pre-A.I. and the beginning of the Big Data era. People were extremely excited about the potential for working with large amounts of data to revolutionise the sciences, ranging from social science to psychology, to urban analytics or urban studies and medicine.
So many things suddenly became possible and people were like, ”this is the microscope”, or any other kind of analogy you can think of in terms of this being a true revolution for the scientific process. Some even went as far as saying, “this is the end of theory, right?” or “this spells the end of hypothesis testing. The data are going to basically speak for themselves”. There was a huge hype of expectation which, as time went on gradually decreased and eventually plateaued to what it is now. It did have a transformative impact on the sciences but to me it became quite obvious working with these data as a student, just how reidentifiable all these types of data potentially were.
Back in the days, we were looking at location data across the country and on the one hand, everyone was talking about how the data were anonymous. As a student, I was working with the data and I could see people moving around on the map, so to speak. And it just blew my mind. It didn’t seem like it would take very much for these data to not be anonymous anymore.
Anonymisation and the way we’ve been using it to protect data have been well documented in the literature. There has also been extensive research on how to properly anonymise data. I think what has taken a bit of time for people to grasp is that anonymisation, in the context of big data, is its own new, different question, and that actually a lot of the techniques that had developed from around 1990 to 2010 were basically not applicable to the world of big data anymore.
This is mostly due to two factors. The first one is just the sheer amount of data that is being collected about every single person in any given dataset that we are interested in, from social science to medicine.
Combining these with social media and the availability of auxiliary data (meaning data from an external source, such as census data) means that not only are there a lot of data about you in those datasets, but there are also a lot of data about you that can be cross-referenced with sources elsewhere to reidentify you. And I think what took us quite a bit of time to get across to people was that this was a novel and unique issue that had to be addressed. It’s really about big data and the availability of auxiliary data. I think that’s really what led a lot of our research into privacy. Regarding anonymisation, we are interested in the conversation around whether there is still a way to make it work as intended given everything we know or do we need to invent something fundamentally new. If that is the case, what should our contribution to a new method look like?
At the end of the day, I think the main message that we have is that anonymisation is a powerful guarantee because it is basically a type of promise that is made to you that the data are going be used as part of statistical models, et cetera, but they’re never going to be linked back to you.
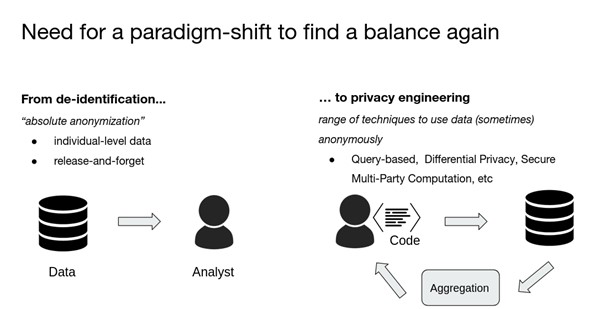
The challenge lies in the way we go about achieving this in practice. Deidentification techniques and principles such as K-anonymity are (unfortunately) often considered a good way of protecting privacy. These techniques which, basically take a given dataset and modify it in one way or another, might have been considered robust enough when they were invented in the 90s and 2000s, but because of the world we live in today and the amount of data available about every single person in those datasets, they basically fall short.
There is a need for a real paradigm shift in terms of what we are using and there are a lot of good techniques out there. Fundamentally, the question comes down to what is necessary for you to make sure that the promise of anonymisation holds true, now and in the future.
Yves-Alexandre de Montjoye
Could you talk to me a little bit about the Observatory of Anonymity and what this project set out to achieve? And then as a second part of that question, are there any new projects that you’re currently working on?
YD: The Observatory of Anonymity comes from a research project published by a former postdoc of mine, and the idea is basically to demonstrate with very specific examples to people, how little it takes to potentially reidentify someone.
Fundamentally, you could spend time trying to write down the math to make sense of why you know for a certain number of reasons that a handful of pieces of information are going to be sufficient in linking back to you. The other option is to look at an actual model of the population of the UK. As a starting point, we know that there are roughly 66 million people living across the country. Even if you take London, there are still 10 million of us. And yet, as you start to focus on a handful of characteristics, you begin to realise very quickly, that those characteristics, when put together, are going to make you stand out and a significant fraction of the time that can mean that you will be the only person in all of the country to match those sets of characteristics.
The interesting part is what do we do?
You’re working within Research Data Management and your team are increasingly dealing with sensitive data and the question of how they can be safely shared?
Clearly there are huge benefits to data being shared in science, in terms of verifying research findings and reproducing the results and so on. The question is how do we go about this? What meaningful measures can you put in place to ensure that you sufficiently lower the risks of harmful disclosure in such a way that you know that the benefit of showing these data will clearly outweigh those risks?
I think from our perspective, it’s really about focusing on supporting modern privacy-ensuring approaches that are fit for purpose. We know that there are a range of techniques; from controlled access to query-based systems, to some of the encryption techniques that, depending on the use case, who needs to access your data, and the size of your dataset would allow someone to use your data, run analysis, and replicate your results fully without endangering people’s privacy. For us, it’s about recognising the right combination of those approaches and how we develop some of these tools and test them.
I think there has been a big push towards open data, under the de-identification model, for very good reasons. But this should continue to be informed by considerations around appropriate modern tools, to safeguard data while preserving some utility. Legally at least, you cannot not care about privacy and if you want to care about privacy properly, this will affect the utility. So we need to continue to handle questions around data sharing on a case-by-case basis rather than imply that everything should be fully open all of the time. Otherwise this will be damaging to the sciences and to privacy.
Yes, it is important to acknowledge that that tension between privacy and utility of research data exists and that a careful balance needs to be struck but this may not always be possible to achieve. This is something that we try to communicate in our training and advocacy work within Research Data Management services. We have adopted a message that can hopefully be helpful (and which originated from Horizon Europe[1]), which states that open science operates on the principle of being ‘as open as possible, as closed as necessary’. In practice this means that results and data may be kept closed if making them open access is against the researcher’s legitimate interests or obligations to personal data protection. This is where a mechanism such as controlled access could play a role.
YD: Just so. I think you guys have quite a unique role to play. A controlled access mechanism that allows a researcher to run some code on someone else’s data without seeing the data on the other hand requires systems of management, authorisation and verification of users, et cetera. This is simply out of the reach of many individual researchers. As a facility or as a form of infrastructure however, this is actually something that isn’t too difficult to provide.
I think France has something called the CASD, which is the Center for Secure Access to Data (or Centre d’Accès Sécurisé aux Données) and this is how the National Institute of Statistics and Economic Studies (INSEE) is able to share a lot of sensitive data. Oxford’s OpenSAFELY in the UK is another great example of this. They are ahead in this regard. We need similar mechanisms when it comes to research data to facilitate replicability, reuse and for validating and verifying results. It is absolutely necessary. But we need proper tools to do this and it’s something that we need to tackle as a collective. No individual researcher can do this alone.
What in your experience are common misconceptions around anonymisation in the context of research data?
YD: I think the most common misunderstanding is a general underestimation of the scale of data already available. Concerns often revolve around a notion of, could someone search another person’s social media and deduce a piece of information to reidentify them in my medical dataset? In the world of big data, I would argue that what we strive to protect against also includes far stronger threat models than this.
We had examples in the US in which you had right wing organisations with significant resources buying access to location data, matching them manually, potentially at scale with the travel record, and other pieces of information they could find about clerics to potentially identify them in this dataset, in an attempt to see if anyone was attending a particular seminar[2].
We had the same with Trump’s tax record. Everyone was searching for the tax record and it turns out that it was available as part of an ’anonymous’ dataset, made available by the IRS and again these were data that were released years and years ago.
They remained online and then suddenly they’re an extremely sensitive set of information that you can no longer meaningfully protect.
This goes back to what you were saying again about anticipating how certain techniques could be used in the future to potentially exploit these data.
YD: Actually, on this precise point, we know from cryptography that good cryptographic solutions are actually fully open and that the cryptographic solution is solid. I can describe to you the entire algorithm. I can give you the exact source code. The secrecy is protected by the process but the process itself is fully open.
If the security depends on the secrecy of your process, often you’re in trouble, right? And so a good solution actually doesn’t rely on you hiding something, something being secret, or you hoping that someone is not going to figure something out. And I think that this is another very important aspect.
And this perhaps goes back again, to the type of general misunderstandings which sometimes arise where someone might assume that because some data have to be kept private, as you were saying, that the documentation behind the process of ensuring that security also has to be kept private, when in fact you need open community standards that can be scrutinised and that people can build upon and improve. This is very relevant to our work in supporting things like data management plans, which require clear documentation.
We have reached our final question: There is arguably a tendency to focus on data horror stories to communicate the limitations of anonymisation (if applied for example without a proportionate risk-based approach for a research project). Are there positive messages we can promote when it comes to engaging with good or sensible practice more broadly?
YD: In addition to being transparent about developing and following best practices as we have just talked about, I think there needs to be more conversations around infrastructure. To me, it is not about someone coming up with and deploying a better algorithm.
We very much need to be part of an infrastructure building community that works together to instill good governance.
There are plenty of examples already in existence. We worked, for example, a lot on a project called Opal which is a great use case of how we can safely share very sensitive data for good. I think OpenSAFELY is another really good case study from Oxford and the CASD in in France as I already mentioned.
These case studies offer very pragmatic solutions, but are an order of magnitude better, both from the privacy and the utility side, than any existing legacy solutions that I know of.
In recent years, universities have become more interested in the data researchers produce. This is partly driven by funder mandates, in the UK in particular the EPSRC Expectations, but also by a concern about research integrity as well as an increasing awareness of the value of research data. As a result, universities are building (or procuring) data repositories and catalogues – and these require metadata.
The world is not short of metadata schemas, and yet there is no widely used standard for how research data should be catalogued (not to replace disciplinary schemes, but simply to enable universities to track their assets and others to discover potentially valuable resources). In my keynote at RDMF14 I questioned whether universities building their own data infrastructures is always the most efficient way to address research data challenges, and I suggested that as a minimum we should aim for an agreement on a simple metadata schema for research data. This would save universities the trouble of having to come up with their own metadata fields, and perhaps, more importantly, such a consensus should help us in discussions with platform vendors and other data repositories. Academics are already using a wide range of disciplinary resources as well as generic repositories, and if we want to be able to harvest, search and exchange data we need a core metadata schema. This would also reduce the burden on academics to have to re-enter metadata manually.
One of the colleagues interested in this idea was Marta Teperek from Cambridge. After RDMF we exchanged the metadata fields currently used for research data at Imperial and Cambridge, with the idea to start a wider discussion. Today Marta and myself attended the kick-off meeting of Jisc’s Research Data Shared Service Pilot where we learned that Jisc are working on a schema for metadata – and there is considerable overlap, also with other initiatives. It seems the time is ripe for a wider discussion, and perhaps even for a consensus on a what could be the minimalist core of metadata fields or research data. Minimalist, to make it easy for researchers to engage; core, to allow institutions to extend it to meet their specific requirements.
To facilitate that discussion, I am going to propose a Birds of a Feather session at next week’s International Digital Curation Conference on this topic. As a starting point I have put together a suggestion, inspired by the fields used in the data catalogues at Imperial and Cambridge:
• Title
• Author/contributor name(s)
• Author/contributor ORCID iD(s)
• Abstract
• Keywords
• Licence (e.g. CC BY)
• Identifier (ideally DOI)
• Publication date
• Version
• Institution(s) (of the authors/contributors)
• Funder(s) (ideally with grant references; can also be “none/not externally funded”)
I would be interested to hear your thoughts – in person at IDCC or another event, or in the comments below. I will update this post with feedback from IDCC.
Update, 23/03/2016: Having discussed this with colleagues at IDCC I thought it useful to clarify something. As I mentioned above there are already several metadata schemas out there, and as you will see from the fields I have proposed above this is not about introducing something new. The issue that we face is that systems either don’t include such fields or they are not mandatory. I would like to explore if we can find a consensus on what is considered the mandatory minimum for discovery and funder compliance (including reporting). For example, institutions need to know who funded an output, but a widely used schema designed for a different purpose may list funder as optional. So in that sense this is not about a new schema as such, but about agreeing what has to be implemented as mandatory in order for us to link systems, reduce duplication etc. That could result in a new schema, but doesn’t have to.
Update, 26/03/2016: Back from IDCC; we had an interesting and wide-ranging discussion. Perhaps not surprisingly, we spent most of the time agreeing on definitions and understanding the use case. Most of the participants of the session were not from the UK and therefore not familiar with UK funder requirements.UK institutions are essentially looking for a pragmatic solution that helps us track datasets, report and meet funder requirements for discoverability. Introducing the concept of discoverability may not have been helpful for the international discussion as it made the proposal sound bigger than it is. We have no plans to replace or supersede disciplinary schemas (where these exist); the aim simply is to be able to point to disciplinary or other external repositories so that someone looking at data from an institutional system can learn that there is a dataset, what it may be about and where to locate it – and, ideally, further information such as detailed disciplinary metadata.
From the discussions with this international audience I am mostly drawing two conclusions: 1) This may be, at least partly, a UK-specific issue. 2) When engaging in discussions with metadata experts there is no such thing as a pragmatic definition – speaking about funder compliance and internal track of datasets for reporting is the more useful question.
Monday 9 – Thursday 12 February 2015 saw data management and curation professionals and researchers descend on London for the 10th annual International Digital Curation Conference (IDCC), held at 30 Euston Square. Although IDCC is focussed on “digital curation”, in recent years it has become the main annual conference for the wider research data management community.
This year’s conference theme was “Ten years back, ten years forward: achievements, lessons and the future for digital curation”.
Tony Hey opened the conference with an overview of the past 10 years of e-Science activities in the UK, in highlighting the many successes along with the lack of recent progress in some areas. Part of the problem is that the funding for data curation tends to be very local, while the value of the shared data is global, leading to a “tragedy of the commons” situation: people want to use others’ data but aren’t willing to invest in sharing their own. He also had some very positive messages for the future, including how a number of disciplines are evolving to include data scientists as an integral part of the research process:
Next up was a panel session comparing international perspectives from the UK (Mark Thorley, NERC), Australia (Clare McLaughlin, Australian Embassy and Mission to the EU) and Finland (Riita Maijala, Department for HE and Science Policy, Finland). It was interesting to compare the situation in the UK, which is patchy at best, with Australia, which has had a lot of government funding in recent years to invest in research data infrastructure for institutions and the Australian National Data Service. This funding has resulted in excellent support for research data within institutions, fully integrated at a national level for discovery. The panel noted that we’re currently moving from a culture of compliance (with funder/publisher/institutional policies) to one of appreciating the value of sharing data. There was also some discussion about the role of libraries, with the suggestion that it might be time for academic librarians to go back to an earlier role which is more directly involved in the research process.
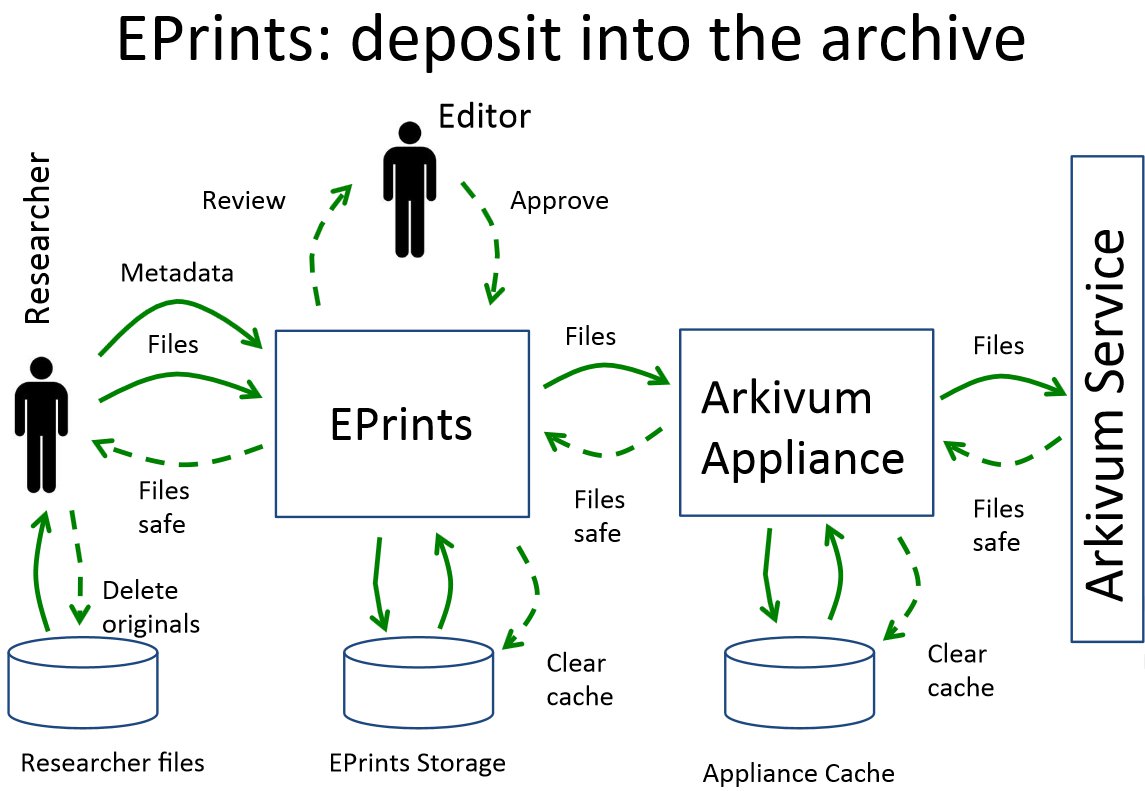
After lunch was a session of parallel demos. On the data archiving front, Arkivum’s Matthew Addis demonstrated their integration with ePrints (similar workflows for DSpace and others are in the works). There was also a demo of the Islandora framework which integrates the Drupal CMS, the Fedora Core digital repository and Solr for search and discovery: this lets you build a customised repository by putting together “solution packs” for different types of content (e.g. image data, audio, etc.).
The final session of the day was another panel session on the subject of “Why is it taking so long?”, featuring our own Torsten Reimer alongside Laurence Horton (LSE), Constanze Curdt (University of Cologne), Amy Hodge (Stanford University), Tim DiLauro (Johns Hopkins University) and Geoffrey Bilder (CrossRef), moderated by Carly Strasser (DataCite). This produced a lively debate about whether the RDM culture change really is taking a long time, or whether we are in fact making good progress. It certainly isn’t a uniform picture: different disciplines are definitely moving at different speeds. A key problem is that at the moment a lot of the investment in RDM support and infrastructure is happening on a project basis, with very few institutions making a long-term commitment to fund this work. Related to this, research councils are expecting individual research projects to include their own RDM costs in budgets, and expecting this to add up to an infrastructure across a whole institution: this was likened to funding someone to build a bike shed and expecting a national electricity grid as a side effect!
There was some hope expressed as well though. Although researchers are bad at producing metadata right now, for example, we can expect them to get better with practice. In addition, experience from CrossRef shows that it typically takes 3–4 years from delivering an infrastructure to the promised benefits starting to be delivered. In other words, “it’s a journey, not a destination”!
Day 2: research and practice papers
Day 2 of the conference proper was opened by Melissa Terras, Director of UCL Centre for Digital Humanities, with a keynote entitled “The stuff we forget: Digital Humanities, digital data, and the academic cycle”. She described a number of recent digital humanities projects at UCL, highlighting some of the digital preservation problems along the way. The main common problem is that there is usually no budget line for preservation, so any associated costs (including staff time) reduce the resources available for the project itself. In additional, the large reference datasets produced by these projects are often in excess of 1TB. This is difficult to share, and made more so by the fact that subsets of the dataset are not useful — users generally want the whole thing.
The bulk of day 2, as is traditional at IDCC, was made up of parallel sessions of research and practice papers. There were a lot of these, and all of the presentations are available on the conference website, but here are a few highlights.
Some were still a long way from implementation, such as Lukasz Bolikowzki’s (University of Warsaw) “System for distributed minting and management of persistent identifiers”, based on Bitcoin-like ideas and doing away with the need for a single ultimate authority (like DataCite) for identifiers. In the same session, Bertram Ludäscher (University of Illinois Urbana-Champaign) described YesWorkflow, a tool to allow researchers to markup their analysis scripts in such a way that the workflow can be extracted and presented graphically (e.g. for publication or documentation).
Daisy Abbot (Glasgow School of Art) presented some interesting conclusions from a survey of PhD students and supervisors:
90% saw digital curation as important, though 60% of PhD holders an 80% of students report little or no expertise
Generally students are seen as having most responsibility for managing thier data, but supervisors assign themselves more of the responsibility than the students do
People are much more likely to use those close to them (friends, colleagues, supervisors) as sources of guidance, rather than publicly available information (e.g. DCC, MANTRA, etc.)
In a packed session on education:
Liz Lyon (University of Pittsburgh) described a project to send MLIS students into science/engineering labs to learn from the researchers (and pass on some of their own expertise);
Helen Tibbo (University of North Carolina) gave a potted history of digital curation education and training in the US; and
Cheryl Thompson (University of Illinois Urbana-Champaign) discussed their project to give MLIS students internships in data science.
To close the conference proper, Helen Hockx-Yu (Head of Web Archiving, British Library) talked about the history of web archiving at the BL and their preparation for non-print legal deposit, which came into force on 6 April 2013 through the Legal Deposit Libraries (Non-Print Works) Regulations 2013. They now have two UK web archives:
An open archive, which includes only those sites permitted by licenses
The full legal deposit web archive, which includes everything identified as a “UK” website (including `.uk’ domain names and known British organisations), and is only accessible through the reading room of the British Library and a small number of other access points.
Workshops
Data Carpentry
Software Carpentry is a community-developed course to improve the software engineering skills and practices of self-taught programmers in the research community, with the aim of improving the quality of research software and hence the reliability and reproducibility of the results. Data Carpentry is an extension of this idea to teaching skills of reproducible data analysis.
One of the main aims of a Data Carpentry course is to move researchers away from using ad hoc analysis in Excel and towards using programmable tools such as R and Python to to create documented, reproducible workflows. Excel is a powerful tool, but the danger when using it is that all manipulations are performed in-place and the result is often saved over the original spreadsheet. This both destroys (potentially) the raw data without providing any documentation of what was done to arrive at the processed version. Instead, using a scripting language to perform analysis enables the analysis to be done without touching the original data file while producing a repeatable transcript of the workflow. In addition, using freely available open-source tools means that the analysis can be repeated without a need for potentially expensive licenses for commercial software.
The Data Carpentry workshop on Wednesday offered the opportunity to experience Data Carpentry from three different perspectives:
Workshop attendee
Potential host and instructor
Training materials contributor
We started out with a very brief idea of what a Data Carpentry workshop attendee might experience. The course would usually be run over two days, and start with some advanced techniques for doing data analysis in Excel, but in the interest of time we went straight into using the R statistical programming language. We went through the process of setting up the R environment, before moving on to accessing a dataset (based on US census data) that enables the probability of a given name being male or female to be estimated.
The next section of the workshop involved a discussion of how the training was delivered, during which we came up with a list of potential improvements to the content. During the final part, we had an introduction to github and the git version control system (which are used by Software/Data Carpentry to manage community development of the learning materials), and then split up into teams to attempt to address some of our suggested improvements by editing and adding content.
I found this last part particularly helpful, as I (in common with several of the other participants) have often wanted to contribute to projects like this but have worried about whether my contribution would be useful. It was therefore very useful to have the opportunity to do so in a controlled environment with guidance from someone intimately involved with the project.
In summary, Data Carpentry and Software Carpentry both appear to be valuable resources, especially given that there is an existing network of volunteers available to deliver the training and the only cost then is the travel and subsistence expenses of the trainers. I would be very interested in working to introduce this here at Imperial.
Jisc Research Data Spring
Research Data Spring is a part of Jisc’s Research at Risk “co-design” programme, and will fund a series of innovative research data management projects led by groups based in research institutions. This funding programme is following a new pattern for Jisc, with three progressive phases. A set of projects will be selected to receive between £5,000 and £20,000 for phase 1, which will last 4 months. After this, a subset of the projects will be chosen to receive a further £5,000 – £40,000 in phase 2, which lasts 5 months. Finally, a subset of the phase 2 projects will receive an additional £5,000 – £60,000 for phase 3, lasting 6 months. You can look at a full list of ideas on the Research At Risk Ideascale site: these will be pitched to a “Dragon’s Den”-style panel at the workshop in Birmingham on 26/27 February.
The Research Data Spring workshop on Thursday 12 February was an opportunity to meet some of the idea owners and for them to give “elevator pitch” presentations to all present. There was then plenty of time for the idea owners and other interested people to mingle, discuss, give feedback and collaborate to further develop the ideas before the Birmingham workshop.
Ideas that seem particularly relevant to us at Imperial include:
A system to make it easier for researchers who currently use Microsoft Access or Excel to move their data to a robust relational database management system and share that data with collaborators.
Packaging up computational experiments (such as weather simulations) into easily verifiable bundles with easy access to the software code, the input parameters and the results.
Looking at how the rules that apply to sensitive data (both general, e.g. Data Protection Act, and specific, e.g. consent forms) can be codified and applied consistently to facilitate inter-institutional collaborations.
Codifying the requirements for data management (how long must it be held for, how large will it get, etc.) so that managing it can be at least partly automated.