We are very excited about this adventure and want to see it a great success so, please, follow that new page and share it with your colleagues and friends!
In the Imperial RSE Team we make extensive use of continuous integration (CI) with GitHub Actions. We use CI to ensure our projects build and are correct across a range of
scenarios (OS, python version, dependency version, etc.). Widely accepted wisdom is that
it is best practice to catch issues early via frequent and thorough CI rather than to
catch them later. This must however be set against the monetary and environment cost of
running unnecessary compute workloads on every push to GitHub. In particular, the
pricing structure of GitHub Actions means workloads run on Windows and MacOS are more
costly (certainly financially and presumably environmentally). This is particularly the
case for private repositories for which Imperial has a fixed budget of minutes.
On Friday, April 26th, 2024, the central Research Software Engineering (RSE) team at Imperial College London hosted the R Dev Day at the Seminar and Learning Centre on the South Kensington Campus. This event, proposed by Dr. Heather Turner, aimed to foster collaboration among both new and experienced contributors interested in contributing to base R. I had the pleasure of co-organising this event alongside Dr. Turner and Dr. Diego Alonso Alvarez.
This year, the annual conference organised by the Society of Research Software Engineering was back on as an in-person event for the first time since 2019. This meant that for many of the college’s central RSE team it was their first opportunity to meet up with RSEs from across the country and further afield. The College was well represented, with five delegates attending from the central team along with RSEs based in specific departments, research groups and teaching staff from the Graduate School.
Overall, the conference was an excellent opportunity to strengthen old connections and make new ones, with plenty of opportunities for networking. The mix of talks, posters, panel discussions, tutorials and walkthroughs covered a wide range of topics from the highly technical to more community-focused issues. Although it is impossible to cover the whole event in detail, we have summarised some of our personal highlights below. The full set of recorded presentations should be available on the SocRSE Youtube channel soon.
Dr Dan Davies from the Imperial RSE team has written a how-to guide based on his experiences with the Django web framework for python. Read the full blog post here.
The RSE team is involved in an increasing number of software projects requiring a front-end web app. The main advantage to having a web app element for your research software is that users can interact with it via a web browser, without having to install anything to their local machine. There are of course downsides, including the need to deploy, host and maintain software somewhere suitable. However, there is a wide range of popular frameworks to make the whole process a lot smoother.
User permissions are an important consideration for any web app. This is not necessarily just to do with overall security, but how you might want different types of users – with different roles – to interact with your software. For example, it is common to require admin users to be able to perform a wide variety of actions, while the majority of users should only be able to perform a small subset of actions. The degree of complexity required will depend on the overall aim.
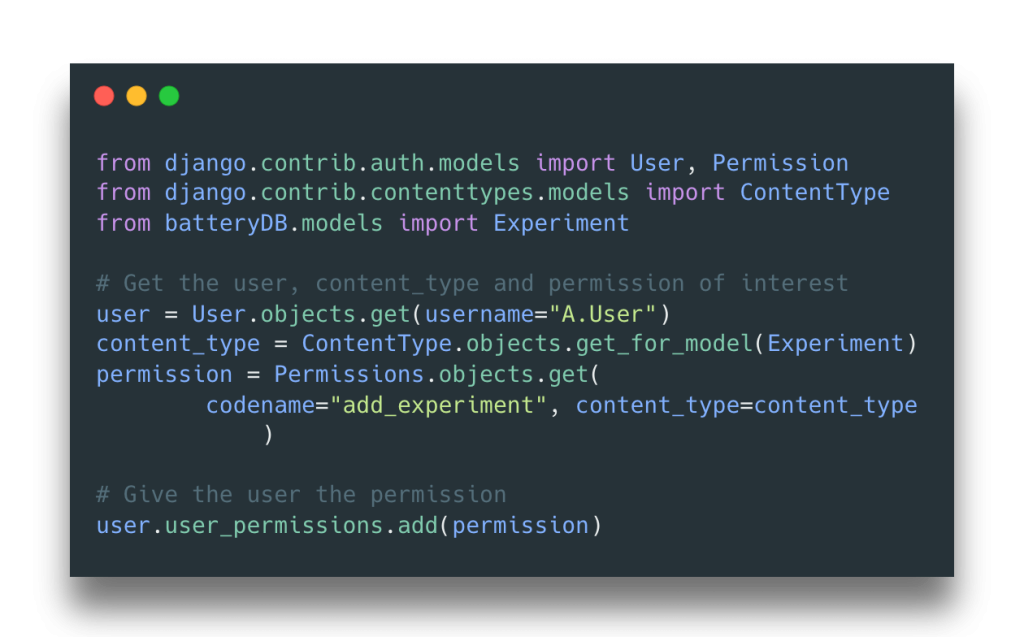
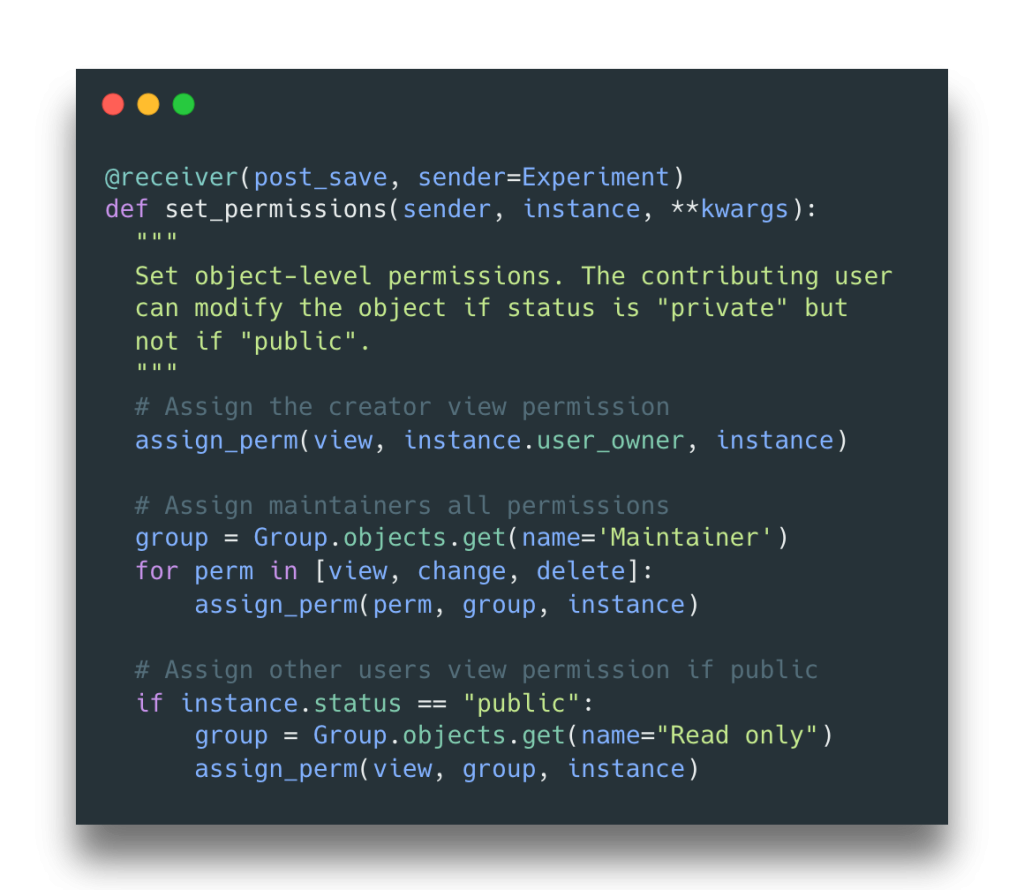
We frequently use the Django web framework, which facilitates the creation of web apps solely in Python. This blog post covers aspects of user management and permissions within Django, which Dan has learned about and implemented while working on a web-based database to store and visualise sets of experimental data. It covers some basics such as how to assign permissions to user and groups of users, as well as more advanced topics such as setting up automatic permissions when specific objects are created. We hope it will be useful to the wider RSE community and beyond!
Fig. 1: Simple permission assignment in DjangoFig. 2: Automatic permission assignment for specific objects in Django.
Jeremy Cohen, EPSRC RSE Fellow, Department of Computing
Building Research Software Communities: Running a workshop on community building and sustainability for the research software community
Michelle Barker, Jeremy Cohen, Daniel Nüst, Toby Hodges, Serah Njambi Rono, Lou Woodley
On Wednesday 17th March 2021, around 50 individuals from a wide range of different countries and time zones came together for the first of two 2-hour sessions that formed our “Building Research Software Communities: How to increase engagement in your community” workshop.
Run as part of the SORSE Series of Online Research Software Events, this workshop brought together an organising team consisting of 3 members of the international research software community and a group of speakers including experts in community engagement and sustainability. In this blog post we provide an overview of the workshop and some of the key messages and outcomes.
This is a summary of a SORSE discussion session, presented by:
Mark Woodbridge, Imperial College London
Vanessa Sochat, Stanford University
Jurriaan Spaaks, Netherlands eScience Center
And featuring contributions from:
Malin Sandström, INCF
Alexander Struck, Humboldt University of Berlin
Introduction
The discussion session “Research Software Directories: What, Why, and How?” was held on September 16 during SORSE, an International Series of Online Research Software Events. As presenters, we each shared efforts to develop and maintain software directories: catalogues to showcase the software outputs of an institution or community. The directories presented were:
GitHub Search as a template for an individual or institution
Each of the above offered several advantages and disadvantages, or were scoped for particular use cases. For example, research-software.nl provides a robust application for serving detailed metrics and metadata for software, however it requires more manual entry. The Research Software Encyclopedia is automated and does not require hosting, but it lacks the same level of metadata. The Imperial College London and GitHub Search research software directories offer much quicker to deploy solutions, but might be too simple for some use cases. The directories are discussed in detail in the following sections. In addition to this set, we suggest the reader take a look at the Awesome Registries list to find additional examples.
Jeremy Cohen, EPSRC RSE Fellow, Department of Computing
This post was compiled by Mark Woodbridge, Jeremy Cohen and Tony Yang of Imperial College’s Research Software Community.
As COVID-19 drives us into uncharted territory, many of us at Imperial will be having our first ever experience of working off-campus for an extended period of time. It, of course, depends on our role, but many members of the College community will be no stranger to mobile working – pitching up at one of the many campus cafes, breakout spaces or a coffee shop, getting out our laptop or mobile device and switching very quickly into a state of focused work. Maybe finishing those next couple of paragraphs of a paper or report, fixing that annoying bug in our scientific code that someone just reported, or responding to an urgent technical query from a collaborator. Sometimes a change of space or environment provides just that little shift in perspective that you need to help solve that challenging technical problem, or get the right wording for that difficult section of the paper, much more quickly than if you’d sat in your office staring at your screen for hours!
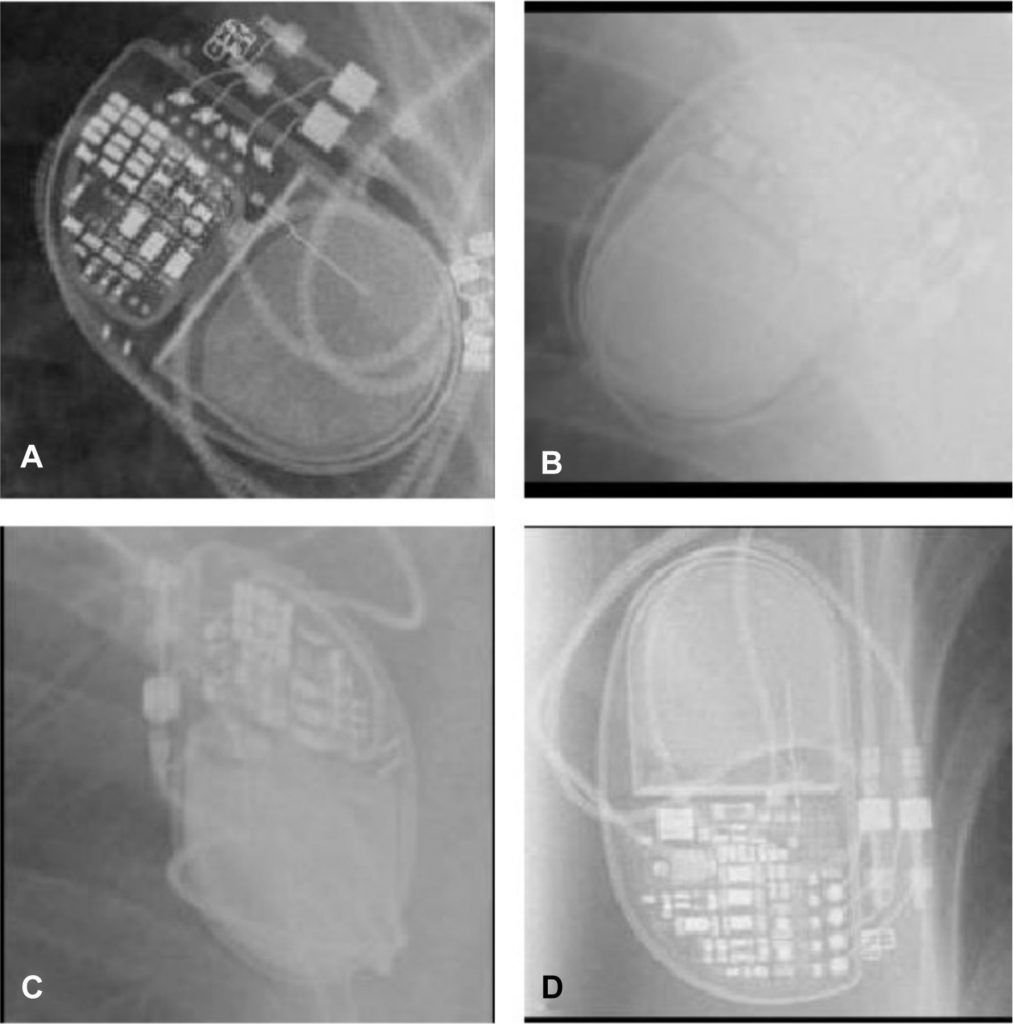
We were really glad to see James Howard (NHLI, Faculty of Medicine) announcing on Twitter that he’d published a Kaggle kernel to accompany his recent publication on MR image analysis for cardiac pacemaker identification using neural networks via PyTorch and torchvision. Sharing code in this way is a great way to promote open research, enable reproducibility and encourage re-use.
We thought it might be helpful to explain how to run similar notebooks on Imperial’s cluster compute service, given that it can provide some benefits while you’re developing code:
You can run parallel interactive and non-interactive jobs that span several days, across multiple GPUs
With James’ permission we’ve lightly modified his notebook and published it in an exemplar repository alongside some instructions to run it on the compute cluster. We hope this can help others to use a combination of Conda, Jupyter and PBS in order to conduct GPU-accelerated machine learning on infrastructure managed by the College’s Research Computing Service – without incurring any cost at the point of use.
Many thanks to James Howard for sharing his notebook and reviewing our instructions