This is the second in a series of posts describing activities funded by our RSE Cloud Computing Award. We are exploring the use of selected Microsoft Azure services to accelerate the delivery of RSE projects via a cloud-first approach.
In our previous post we described the deployment of a fairly typical web application to the cloud, using an Azure Virtual Machine in place of an on-premise server. Such VMs offer familiarity and a great deal of flexibility, but require initial provisioning followed by ongoing maintenance and monitoring. Our team at Imperial College is increasingly using containers to package applications and their dependencies, using Docker images as our unit of deployment. Can we do better than provisioning servers on a case-by-case basis to get web applications into production, and thereby more rapidly deliver services to our users?
The Azure App Service provides a solution named Web App for Containers, which essentially allows you to deploy a container directly without provisioning a VM. It handles updates to the underlying OS, load balancing and scaling. In this post we’ll demonstrate how to run pre-built and custom Docker images on Azure, without having to manually configure any OS or container runtime. As previously, we’ll use the Azure Cloud Shell, and arguments that you’ll want to set yourself are highlighted in bold.
Getting started
First of all we create an App Service plan. This only needs to be performed once for your active subscription:
az group create --name myResourceGroup --location "West Europe"
az appservice plan create --name myAppServicePlan --resource-group myResourceGroup --sku S1 --is-linux
Deploying a pre-built, public container image
It’s then just one command to run a Docker container. In this case we’ll deploy Nginx using its Docker Hub image:
az webapp create --resource-group myResourceGroup --plan myAppServicePlan --name ic-nginx --deployment-container-image-name nginx
We can then visit our public site at https://ic-nginx.azurewebsites.net/
You can use a custom DNS name by following these further instructions. Note that the site automatically has HTTPS enabled.
Decommissioning the webapp (thereby avoiding any further charges) is similarly straightforward:
az webapp delete --resource-group myResourceGroup --name ic-nginx
Deploying a custom container image
Running your own app is as simple as providing a valid container identifier to az webapp create. This can point to either a public or private image on Docker Hub or any other container registry, including Azure’s native registry.
For demonstration purposes we’ll build a Datasette image to publish the UK responses from the 2017 RSE Survey. Datasette is a great tool for automatically converting an SQLite database to a public website, providing not only a means to browse and query the data (including query bookmarking) but also an API for programmatic access to the underyling data. It has a sister tool, csvs-to-sqlite, that takes CSV files and produces a suitable SQLite file.
First we need to install both tools, download the survey data, and convert it from CSV to SQLite:
pip install https://github.com/simonw/csvs-to-sqlite/zipball/master datasette
curl -O https://raw.githubusercontent.com/softwaresaved/international-survey/master/analysis/2017/uk/data/cleaned_data.csv
csvs-to-sqlite --table responses cleaned_data.csv uk-rse-survey-2017.db
Then we can create a Docker image containing the data and the Datasette app with one command, annotating with the appropriate licence information:
datasette package uk-rse-survey-2017.db
--tag mwoodbri/uk-rse-survey:2017
--title "UK RSE Survey (2017)"
--license "Attribution 2.5 UK: Scotland (CC BY 2.5 SCOTLAND)"
--license_url "https://creativecommons.org/licenses/by/2.5/scotland/deed.en_GB"
--source "The University of Edinburgh on behalf of the Software Sustainability Institute"
--source_url "https://github.com/softwaresaved/international-survey"
Then we push the image to Docker Hub:
docker push mwoodbri/uk-rse-survey:2017
And, as previously, create an Azure Web App:
az webapp create --resource-group myResourceGroup --plan myAppServicePlan --name rse-survey --deployment-container-image-name mwoodbri/uk-rse-survey:2017
Using Datasette
After a brief delay the app is publicly available: https://rse-survey.azurewebsites.net/
Note that the App Service automatically detects the right port to expose (8001 in this case) and maps it to port 80.
Datasette enables you to run and bookmark SQL queries, for example this query which lists the contributors’ organisations in order of the number of responses received:
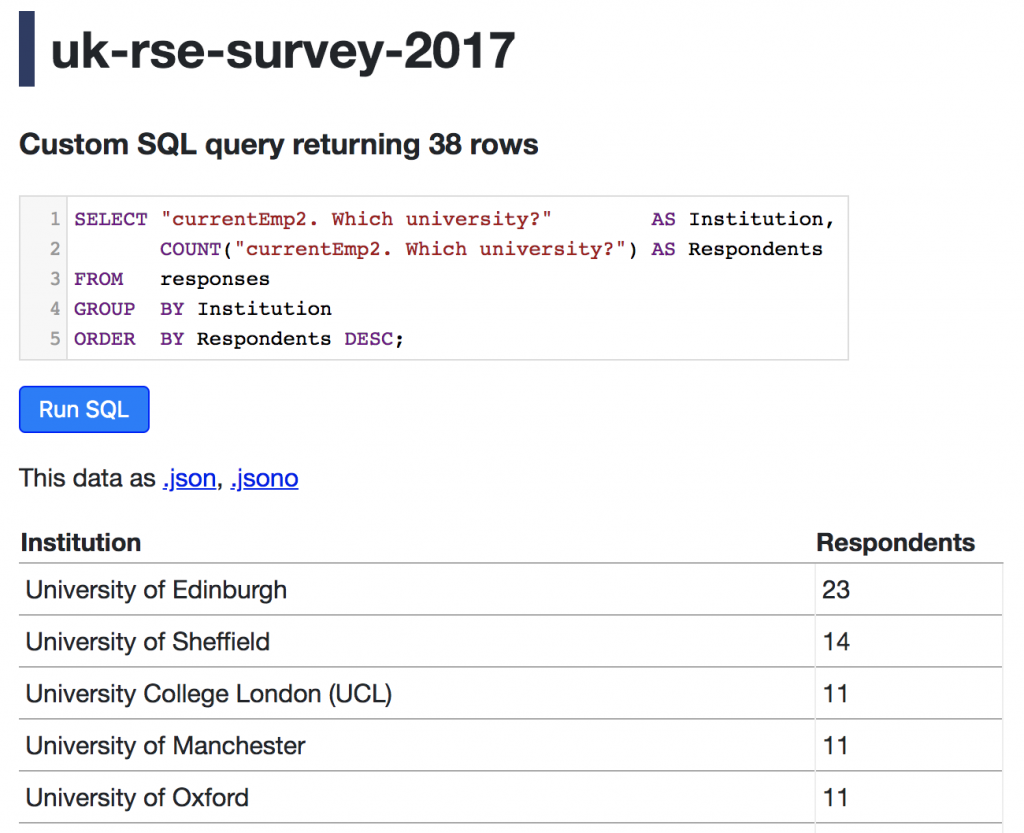
Private registries
If you’re hosting your images on a publicly accessible that requires authentication then you can use the previous az webapp create command into two steps: one to create the app and then to assign the relevant image. In this case we’ll use the Azure Container Registry but this approach is compatible with any Docker Hub compatible registry.
First we’ll provision a container registry. These steps are unnecessary if you already have one:
az acr create --name myrepo --resource-group myResourceGroup --sku Basic --admin-enabled true
az acr credential show --name myrepo
Then we can login to our private registry and push our appropriately tagged image:
docker login myrepo.azurecr.io --username username
docker push myrepo.azurecr.io/uk-rse-survey:2017
Finally we can create our webapp and configure it to be created using the image from our private registry:
az webapp create --resource-group myResourceGroup --plan myAppServicePlan --name rse-survey
az webapp config container set --resource-group myResourceGroup --name rse-survey --docker-custom-image-name myrepo.azurecr.io/rse-survey --docker-registry-server-url https://myrepo.azurecr.io --docker-registry-server-user username --docker-registry-server-password password
The end result should be exactly the same as when using the same image but from the public registry.
Tidying up
As usual, you can delete your entire resource group, including your App Service plan, registry (if created) and webapps by running:
az group delete --name myResourceGroup
Summary
In this post we’ve demonstrated how a Docker image can be run on Azure using one command, and how to build an deploy a simple app that presents a simple interface to explore data provided in CSV format. We’ve also shown how to use images from private registries.
This approach is ideal for deploying self-contained apps, but doesn’t present an immediate solution for orchestrating more complex, multi-container applications. We’ll revisit this in a subsequent post.
Many thanks to the Software Sustainability Institute for curating and sharing the the RSE survey data (reused under CC BY 2.5 SCOTLAND) and Simon Willison for Datasette.
Read Cloud-first: Rapid webapp deployment using containers in full


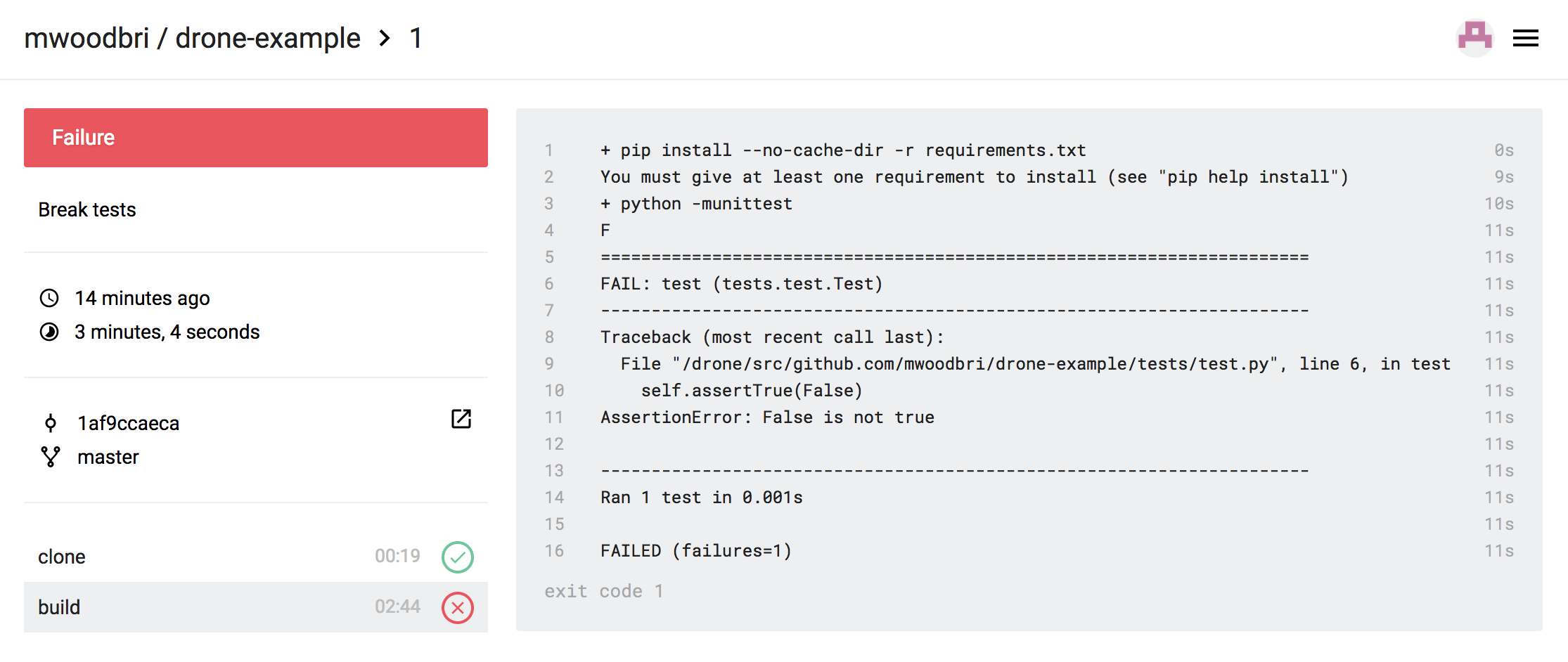
 In this post we’ll demonstrate how to run deploy a simple scheduled task: a
In this post we’ll demonstrate how to run deploy a simple scheduled task: a